

Watch Your Language, Part 1 | Machine Yearning 001
Why Size Matters and What to Do About It

Hello and welcome!
I originally planned this week to dive into Google’s recently released Switch Transformer language model and how it differs from previously published models like GPT-3. Instead, I will be splitting this topic into two parts:
Part 1 (this post) will explore language models at a high level, with some fun and some dangerous applications.
Part 2 will compare current state-of-the-art models like the Switch Transformer, GPT-3, and its open-sourced alternative GPT-Neo, through a more technical and economic lens.
For now, welcome to the sometimes silly, sometimes concerning, but always interesting world of language models. Here’s why they matter and why you should care.
🔬Long Take: Language Models for Fun and Profit
Before I start, it’s probably best to quickly state what a “language model” is.
Put simply, given the context of preceding words, a language model predicts what the next word in a sentence will be.
That’s it. Simple as that.
Believe it or not, you already use language models in your daily life. Gmail’s ‘Smart Compose’ feature and the predictive keyboard on your iPhone are common examples.

Researchers train these models on large collections of text documents (corpora), which contain millions and millions of words and sentences in natural language. Some of the most common corpora include sets from Wikipedia, books in the public domain, internet news, even Shakespeare. Importantly, the kinds of corpora researchers choose to train on have significant implications for the kinds of words the model predicts.
“You are Hagrid now.”
Back in late 2017 one studio trained a language model on Harry Potter books, then used it to independently generate a hilarious new chapter called Harry Potter and the Portrait of What Looked Like a Large Pile of Ash. I definitely recommend reading the whole thing, but here are my favorite excerpts:
Leathery sheets of rain lashed at Harry’s ghost as he walked across the grounds toward the castle. Ron was standing there and doing a kind of frenzied tap dance. He saw Harry and immediately began to eat Hermione’s family.
Ron’s Ron shirt was just as bad as Ron himself.
“If you two can’t clump happily, I’m going to get aggressive,” confessed the reasonable Hermione.
“Not so handsome now,” thought Harry as he dipped Hermione in hot sauce.
The pig of Hufflepuff pulsed like a large bullfrog. Dumbledore smiled at it, and placed his hand on its head: “You are Hagrid now.”
At best, it’s a whimsical, silly romp that actually does sound Rowling-esque. But since this model is trained only on Harry Potter books, with a measly total of 1,084,170 words, its performance is rather limited. Professional writers and copy-editors had to be employed to prune the generated text, and you shouldn’t expect this to perform very well on a task like Smart Composing email replies.
“Writing more while thinking less.”
Another silly, but more concerning real-world example is a productivity blog created by Berkeley student Liam Porr last year. Reportedly, it only took a few hours of playing with OpenAI’s popular language model GPT-3 (more on this in a bit) for Porr to think of an experiment to run: first, he would feed the model a headline and introduction for a blog post as inputs. Next, given that context, the model would go on to generate several versions of full-length self-help and productivity blog posts based solely on just the headline and intro.
Determining these inputs wasn’t difficult. He would make quick trips to Medium and Hacker News to see what’s trending, copy something similar, and that would get the job done. Under the pseudonym “Adolos”, he began publishing near-daily posts to his productivity blog over a two-week period:
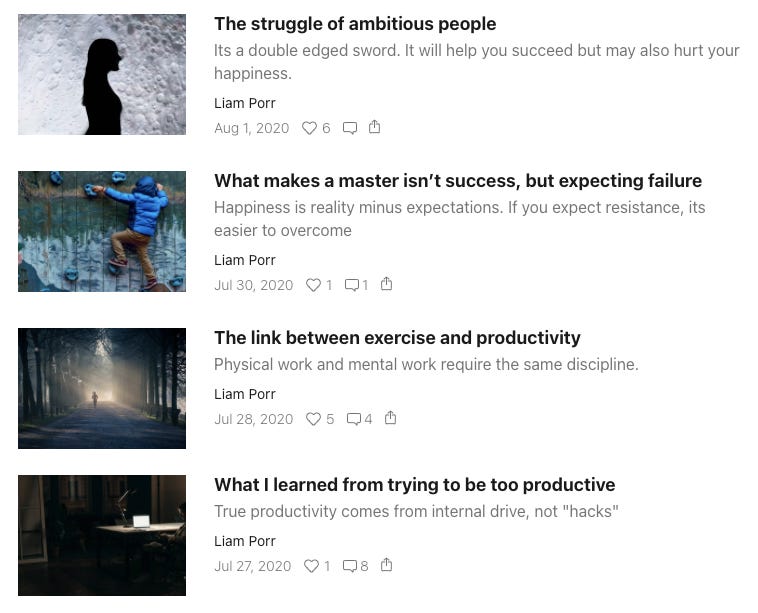
This was an innocent enough idea, and in practice the blog posts seemed so familiarly written and the language so sensible that almost no one could see through the ruse.
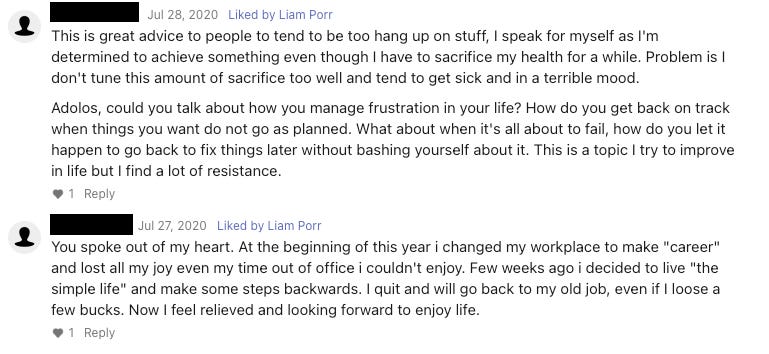
In a surprising turn of events, many who suspected these posts were AI-generated were actually criticized and downvoted by the community!
Just before fessing up to the whole charade, his final, human-written blog post “What I Would Do with GPT-3 If I Had No Morals” pulled an O.J. and described in hypothetical detail how one might go about pulling this off.
While the output is not perfect, you can easily curate it to something that's convincing. This will make it so easy for people to just pump out clickbait articles to drive traffic. It would be pretty simple to do actually.
First thing you would need to do is come up with a name. If it were me, I’d name it after the Greek god of deception or something like that just to be clever. Then I’d just stick an “A” in front so nobody gets suspicious.
After that, I’d make a substack because it takes no time to set up. Once thats done you have to come up with some content. GPT-3 isn’t great with logic, so inspirational posts would probably be best, maybe some pieces on productivity too.
Porr observed that GPT-3 is “good at making pretty language, and … not very good at being logical and rational.” Given those constraints, what better blogging category to pick than productivity and self-help?
Size matters
On a more serious note, that these communities were so easily duped with such little effort on Porr’s part raises serious questions. How is it that language models like GPT-3 are able to generate such convincing language?
When it comes to building effective language models, generally speaking the more natural language data included in the training phase, the more convincing the generated outputs will be.
Now remember, models themselves aren’t malicious, they just amplify whatever biases exist in the data used to train them. Massive language models? Even more so.
Two ___ Walked Into a ___
Here’s where things get dicey. Taking the outputs of massive language models for granted can have dire consequences, well beyond occasionally duping a bunch of Hacker News readers. Abubakar Abid, a Stanford PhD candidate, demonstrated one such example using the GPT-3 demo in August of last year. Watch the video below to see what happens when the model is fed a sentence that starts with “Two Muslims”…

Compared to any other religious group, preceding a sentence with “Two Muslims” generated violent content about 9x as frequently.

Abid sees this sort of anti-Muslim bias as “persistent” in many massive language models.
Now, why might this be happening? These models are built on massive datasets with billions and billions of tokens from many different sources, like books, news, Wikipedia, and website text. For these datasets, think about what bias the authors, editors, and journalists may have had going into the publishing process for the documents in these corpora.
What language, what country, what time period were they written in?
What percentage of documents come from a time period, say, post-9/11, when the frequency of anti-Islamic sentiment and hate crimes rose and persisted for many years?
The bigger these models get, the more difficult it is to perform studies that spot these kinds of biases. Without proper scrutiny and auditing, training on massive text datasets carte blanche will encode sometimes extreme but otherwise unhelpful biases into our language models.
The Replicability Crisis
Because these models are so big, the arms race is contributing to a replicability crisis where very few entities have the capital and resources to train and run said models from scratch. We end up having to rely on the publisher (Google, OpenAI, etc.) to check their homework.
While some researchers are alright with this approach - let Google-sized entities pre-train and publish these large general models, and have smaller entities customize them for specific applications - this obscures peer reviewers’ and third parties’ ability to spot biases that can be used to discriminate, radicalize, or justify extreme violence.
What can we do about it?
Understanding how these biases show up is critically important. That’s the first step to solving the problem.
Ask the right questions.
I alluded to this before. Be inquisitive about the datasets used for training. What are their sources, on what time window were they collected, etc.. Are there alternative datasets available which may mitigate or de-risk unhelpful bias?
Conduct regular audits.
Structured reviews and audits of these popular datasets often yield surprising results. To borrow a computer vision example, the Tiny Images dataset from MIT (comprised of 80 million labeled 32x32 pixel images used to train and benchmark computer vision models) was removed from the public domain after a more thorough review revealed some highly inappropriate, derogatory annotations (emphasis mine):
The dataset includes, for example, pictures of Black people and monkeys labeled with the N-word; women in bikinis, or holding their children, labeled whores; parts of the anatomy labeled with crude terms; and so on – needlessly linking everyday imagery to slurs and offensive language, and baking prejudice and bias into future AI models.
Personally, I think there’s much more to learn from auditing and pruning than outright removal, but tough calls have to be made. Unfortunately for MIT, the images themselves were too small for manual review, so the lab elected to remove the dataset in its entirety.
When creating datasets, do your diligence.
The lab (CSAIL) also admitted that in creating the dataset, they “automatically obtained the images from the internet without checking whether any offensive pics or language were ingested into the library.” Any downstream models making use of the Tiny Images dataset, or any large pre-trained model built on it, would therefore mistakenly suggest problematic, causal links not grounded in reality.
Open-source where possible.
For now, GPT-3 is under lock-and-key on an exclusive license to Microsoft. The source code was never released to the public, which has obscured the ability for researchers to examine its biases in detail.
Fortunately, a team called EleutherAI is working to open-source GPT-3 through a parallel effort called GPT-Neo. Areas of improvement include a dedicated team of curators who have performed “extensive bias analysis” on training data, and in some cases, excluded otherwise popular datasets they felt had “unacceptably negatively biased” content. Compared to GPT-3’s 5 datasets, GPT-Neo has a more diverse mix of 22 smaller datasets.
Moving forward
It’s important to remember that machine learning models are, in their simplest form, just pattern recognition tools. They are not free of subjectivity. Any bias that exists in the training data will be amplified. So there is an ethical responsibility on the part of both researchers and customers to think deeply about their models’ application and misapplication.
In a world where proliferated, unmoderated fake news on Facebook directly contributed to the systemic genocide of a Muslim ethnic minority (Rohingya Muslims in Myanmar), it isn’t a stretch to imagine how malicious actors could, with a botnet and a language model, procedurally generate enough conspiracies and hateful content to dupe individuals, communities, and governments alike.
At the end of the day, I would caution against measuring progress by size alone, and recommend a more nuanced approach which takes extreme bias detection into consideration. To make effective use of these large models you need capital and resources belonging to a select few, which concentrates research and publishing power, de-emphasizes practical relevance for most institutions, and increases systemic risks when left unchecked and unchallenged.
Bonus Content
These are articles, reports, videos, and more worth checking out that didn’t get a featured mention this issue.
📚 Reading
💲 AI in the Market
From China to San Francisco: The Location of Investors in Top U.S. AI Startups (CSET)
The most popular foreign investors in top US A.I. startups are out of - you guessed it, China.
Comparing Corporate and University Publication Activity in AI/ML (CSET)
While universities technically produce more numerous AI papers, corporations generate the most citations for published work.
🏛 Government & Policymaking
The Biden Administration’s AI Plans: What to Expect (MIT Technology Review)
Three takeaways: first, the President elevated the director of the Office of Science and Technology Policy (OSTP) to a cabinet-level position. Then, he named a prominent sociologist as deputy director, who may be more mindful of encoded bias to algorithm inputs. Finally, his Secretary of State described the pursuit of AI standard-setting against ‘techno autocracies’ (i.e. China) in particularly dramatic terms.
US has ‘moral imperative’ to develop AI weapons, says panel (The Guardian)
For about eight years, a coalition of non-governmental organizations have been pushing for an international treaty banning the use of autonomous (read: no humans in the loop) weapons. Interesting takes in here as to why (“human control is necessary to… assign blame for war crimes.”). The National Security Commission on Artificial Intelligence, led by former Google CEO Eric Schmidt, acknowledges risks but does not recommend a ban, saying such weapons will contribute to a cleaner, safer battlefield, free of human error.
We’ll definitely cover this in a future issue, but for now keep this in mind: genetic diversity is a crucial line of defense for any species. If our autonomous weapons can all fall victim to the same adversarial attacks, our defense infrastructure becomes far more fragile.
🔍 Hidden Biases
OpenAI and Stanford Researchers Call for Urgent Action to Address Harms of Large Language Models Like GPT-3 (VentureBeat)
“Lies travel halfway around the world before the truth ties its shoes.” Perpetuating disinformation is only one of many malicious applications of large, unaudited, pre-trained language models.
Predictive Policing is Still Racist - Whatever Data it Uses (MIT Technology Review)
Predictably, supervised algorithms trained on past crime data make irresponsible causal fallacies between race, crime, and recidivism, no matter which way researchers slice it. They’re having a tough time finding a technical fix; in the meantime, they advocate for a political solution, but officials are reluctant to abandon the technology.
🔧 Hardware & ASICs
Alibaba Unveils Its First AI ASIC, Hanguang 800 (CNBC)
Older news (Sep 2019), but still important. Large companies reliant on AI for competitive advantages have been developing their own hardware in-house, like Google and its custom tensor processing units (TPUs). Alibaba’s Hanguang 800 can allegedly speed up computing tasks by 12x in crucial tasks for e-commerce (product search, translation, recommendations, etc.). Eventually, Alibaba can lease out their cloud compute and Hanguang 800 capacity to other companies, a lá AWS.
Baidu in Talks to Raise Money for a Standalone AI Chip Company (CNBC)
In the face of global semiconductor tariffs, Chinese tech enterprises have realized the need to invest in their own semiconductor capacity. GGV Capital and IDG Capital are advising. These industries don’t just pop up overnight, but compute (and the resources to produce it) is becoming more valuable than oil. Keep an eye out for pundits quantifying “compute independence” on an international basis.
Tencent Invests in Chinese AI Chip Startup as Part of $279 Million Funding Round (CNBC)
The startup in question is “Enflame Technology,” headquartered in Shanghai. CITIC, CICC Capital, and Primavera are involved.
NeuReality Emerges From Stealth with $8m Seed for AI Compute Infrastructure (HPCwire)
NeuReality is an Israeli semiconductor startup building scalable AI-specific chipset. They recently appointed Naveen Rao to their Board of Directors; Rao founded the first AI chip startup, Nervana Systems, later acquired by Intel.
🎧 Listening
The First AI Chip Startup with Naveen Rao, Nervana Systems (Spotify)
Naveen Rao shares firsthand experience with the ‘trickle-down problem’ after Nervana Systems was acquired by Intel. Listen in for why the chipmakers of today will most likely not be the AI ASIC champions of tomorrow.
🎥 Watching
How Can Human-Centered AI Fight Bias in Machines and People? (MIT Sloan)
Prevailing wisdom assumes that the role of algorithms “is to correct the biases that humans have… [t]his follows the assumption that algorithms can simply come in and help us make better decisions – and I don’t think that’s an assumption we should operate under.
Thanks for reading!
Machine Yearning is a collection of essays and news on the intersection between AI, investing, product, and economics, light on technicals but heavy on relevance. Think of it as a casual chat about AI over coffee (or any other preferred beverage).
Ryan Cunningham is an AI Product Manager, strategist, and ex-investment banker. Today he leads applied AI strategy and new verticals at Spiketrap, an NLP-as-a-service company. He spent 4 years at Uber and is currently studying Artificial Intelligence part-time at Stanford, with a BS in Finance and Economics from Georgetown University.
Any suggestions or items you want to see? Shoot me an email at rydcunningham@gmail.com or hit me up on Twitter / LinkedIn / Clubhouse @rydcunningham.