

DeepSeek and the End of an Era
commoditized intelligence and the rebalancing of AI superpowers

I've spent the past few days drafting this essay, and it's the longest I've published to date. Budget ~20-30 minutes to digest it, best read over coffee.
I kept this long because I wanted the arguments in a complete form, and to discourage readers jumping to conclusions from unqualified headlines and half-truths. Fortunately, some major voices have provided fulsome commentary by now, so we get a complete and timely picture vs. pigeonholing into any one narrative.
Introduction
Over the holidays, a Chinese AI lab called DeepSeek released a pair of large language models which rocked the markets and AI industry. For most, the prevailing wisdom had been that bigger was better - raw compute power, ever-larger parameter counts, and economies of scale were the only path to achieving state-of-the-art intelligence that could compete with the top players.
Except DeepSeek trounced them all with a tiny fraction of their resources. Reportedly, DeepSeek-V3 was trained on just $5.6M worth of compute1, compared to $78M for GPT-42 and over $100M for LLaMa 3 405B.3
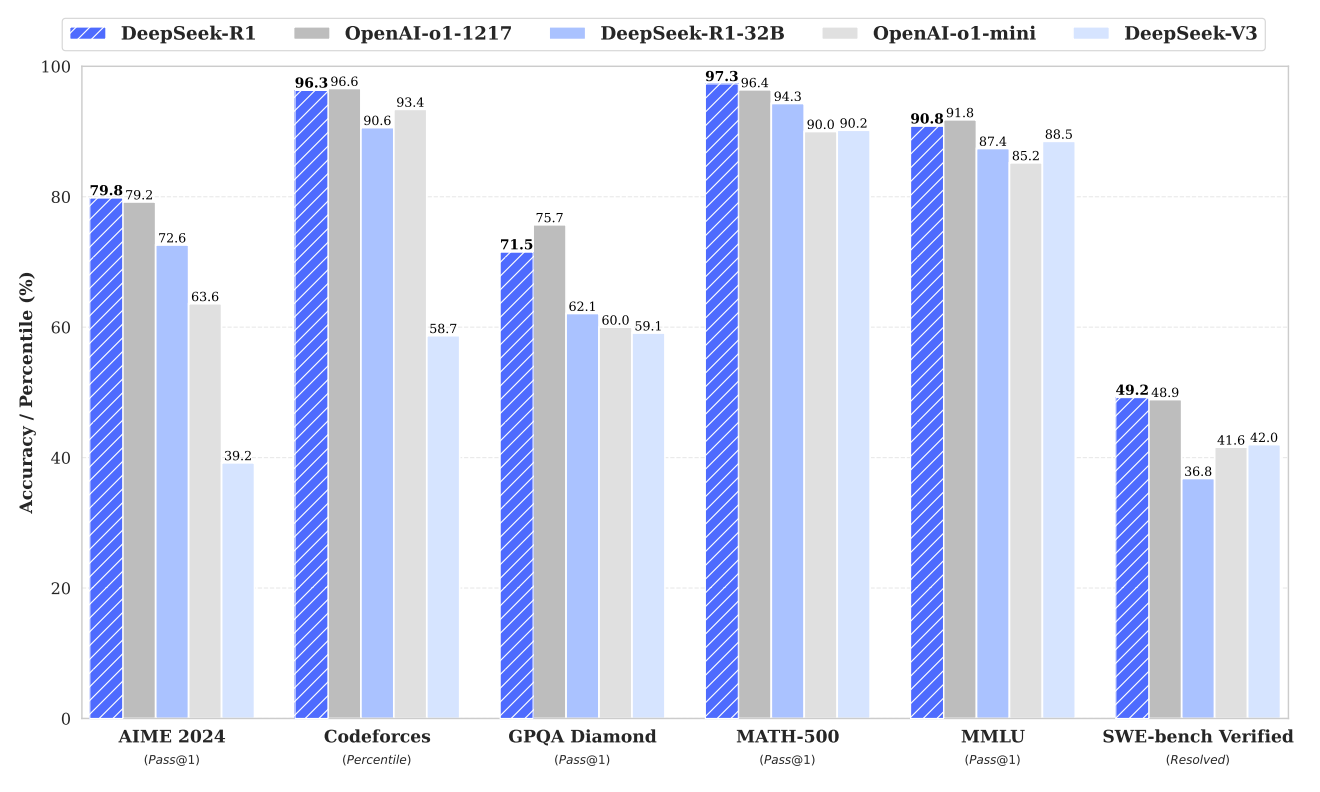
This was a shot across the bow of the AI industry's reigning "sovereigns" - the super-scale labs whose strategy rests on cornering the market for AI capital, compute, and energy. It's the first domino to fall in a chain reaction that will reshape the technopolitical and economic landscape of AI as we know it - to no surprise to watchful observers, but a major surprise to the sovereign ecosystem.
Here's how we'll break it down:
First, I'll demystify the architectural decisions that contributed to DeepSeek's efficiency gains.
Second, I'll lay out strategic implications for "sovereigns," the super-scale AI labs whose entire strategy rested on accessing capital, compute, and energy resources on the scale of nation-states.
Third, we'll assess the immediate market fallout and compelling emergent investment themes.
Fourth, cover the geopolitical reckoning with example reactions from American and Chinese stakeholders.
Ultimately, I argue that DeepSeek's breakthrough validates the AI commoditization thesis, challenges the sustainability of the sovereign AI model, and heralds a new era of AI diffusion across players and industries - one that demands a strategic reset from stakeholders looking to avoid the "sovereign trap".
Before diving in, keep in mind this essay is a deliberately provocative take meant to challenge orthodoxy. I’m an investor in companies like Fastino and Positron that compete with sovereign AI strategies, and am a vocal advocate for open-source models, which may color my analysis of centralized AI power structures. I’ve aimed for objectivity, but please weigh my affiliations against the merit of my arguments.
1. The Efficiency Revolution
When talking about great power competitions, especially in the tech context, I often talk about "diffusion," a framework Jeffrey Ding (ChinAI, George Washington University) introduced to characterize the spread of an innovation throughout a population or ecosystem.
To summarize, general purpose technologies (GPTs) like electricity or broadband gradually "diffuse" across many industries which make use of their horizontal capabilities. This contrasts against the "leading sector" approach which emphasizes concentrated upheavals in singular technologies, like railroads or automobiles, which while impactful are not as portable across industries.
Leading sector technologies lend themselves to monopolization, while GPTs benefit greatly from tailwinds that accelerate societal adoption, like drastically lowering the cost of inputs, or widening the base of engineering skills that take advantage of the GPT. Nation-states' success in leveraging these innovations depends on how effectively their institutions respond to those needs.
Up to now, western institutions in the sovereign AI ecosystem have behaved very much in a leading sector approach, emphasizing concentration of talent, compute, energy, and capital in a handful of captured labs. But DeepSeek's revolutionary efficiency gains was an ecosystem earthquake, causing many to rethink their priors and question the sustainability of the sovereign AI model against an impending tsunami of efficient diffusion.
DeepSeek's Architectural Innovations
First, let's get up to speed. There are two models DeepSeek released recently, both with their own implications:
DeepSeek-V3 is an advanced language model that tops leaderboards among open-source models, despite its puny compute resources. It builds upon the successful techniques discovered in prior DeepSeek model iterations.
DeepSeek-R1 is a "reasoning model," a modified version of DeepSeek-V3 developed using pure Reinforcement Learning (GRPO). It is fully open-source, MIT-licensed, and reportedly performs on par with leading AI models. The model was released on January 20, 2025, and is claimed to be 20 to 50 times more efficient than its primary competitor, OpenAI's o1.
A "reasoning" model is an evolved LLM which uses "chain of thought" to improve its problem-solving capabilities. Basically, it thinks out loud to itself before giving an answer. This usually leads to higher quality answers, especially in complex tasks, workflows, and critical thinking problems. R1's efficiency gains stem from the same algorithmic and recipe improvements that went into V3, so I often refer to them both in the collective.
To keep it simple, think of DeepSeek's breakthrough as building a more fuel-efficient engine rather than building bigger gas tanks. The team introduced four key innovations that, working together, deliver the same performance as models 10x their size while using a fraction of the resources. Let's break those down:
1. FP8 mixed-precision training framework
At its core, this is about being smarter about how we store numbers in AI models. Traditional models insist on extreme precision, storing all parameter weights in 16-bit or 32-bit precision, like measuring your height down to the nanometer.
DeepSeek proved you don't need that level of precision for every calculation, choosing instead to use 8-bit precision wherever possible without inducing quality loss. They're not the first to implement this approach, but it is the first to do it on such a large scale. Several research teams have previously implemented mixed-precision training approaches, such as Microsoft's FP8-LM framework4 and BitNet56 (which uses binary weights, seriously pushing the boundaries of low-precision training).
DeepSeek's implementation yields a 40% reduction in memory usage while maintaining model quality. This is a direct challenge to the "more compute = better AI" orthodoxy that's dominated the field up to now.
For the technically curious, DeepSeek's implementation includes specialized hardware optimizations and dynamic range adaptation that prevent information loss, detailed in their technical report.
2. Multi-head Latent Attention (MLA)
Traditional transformer attention is like having to remember every word you've ever read to understand the next sentence. Developers try to improve prediction performance with larger and larger context windows, but without addressing _how_ information is stored and retrieved, they're anchored to an exponential scaling problem.
In contrast, DeepSeek's MLA mechanism is more like human memory: it focuses on key concepts and relationships rather than raw data. Instead of storing the entire context window in memory, DeepSeek's MLA mechanism stores a latent vector representation of the context window, compressing the information into a smaller, more manageable size - by 93.3%.
This reduces memory complexity from O(n²) to O(n·k), where k is a constant - a game-changing improvement for scaling. It enables models to handle context windows 4x longer while using 60% less memory.
The full architectural details are available in their MLA paper published last year7, but the key takeaway is simple: longer context windows no longer mean exponentially higher costs.
3. Auxiliary-loss-free MoE
A mixture-of-experts (MoE) model like DeepSeek's is a lot like a hospital. You have lots of specialists on call, and when patients come through the door, you want to route them to the right specialist who can give them the best help. That's why it's called "mixture" of experts - the full 671B model is actually a lot of smaller expert models stitched together.
You want to make sure each patient sees the right specialist, but time is money, and you don't want doctors sitting idle while others are overwhelmed. Traditional Mixture of Experts (MoE) models face the same challenge - they need complex "traffic control" systems (auxiliary losses) to route work efficiently among specialist neural networks.
If this sounds familiar, it's because it's conceptually similar to the model routers we discussed in Betting on Model Marketplaces
While external routers can use fancy techniques to choose between different models, internal MoE routing traditionally required crude balancing mechanisms that often hurt performance by forcing work to less-qualified experts, just to maintain balance. Like sending patients to a dermatologist when they really need a cardiologist, just because the dermatologist's waiting room is empty.
DeepSeek's innovation is a new gating mechanism that achieves natural load balancing through the architecture itself, by considering both expert specializations and current load. Their implementation modifies the traditional sparse gating function.8
When combined with MLA, this approach yielded a 42.5% reduction in training costs and a 5.76x boost in throughput. Using just 21B parameters per token, DeepSeek-V2 matched the performance of models 2-3.5x its size, like Mixtral-8x22B and LLaMa-3 70B, on a drastically lower compute budget.

This matters because MoE architectures are one of the most promising paths to scaling AI capabilities without linear compute increases. While Mistral's Mixtral9, Microsoft's Retentive Network10, and Google's Switch Transformer11 demonstrated MoE's potential (and GPT-4 is rumored to use it12), auxiliary losses remained a key bottleneck until now. DeepSeek's implementation found a path to more efficient scaling without complex load balancing schemes.
4. Multi-token prediction system
Traditional language models generate text one token at a time - like someone reading a book word by word. In order to predict the next token in a sequence, the model draws on both its world knowledge and prior tokens in the current context. Sequential generation therefore creates practical memory and throughput bottlenecks in real-world applications, as the amount of context in the conversation grows and grows.
To get around this, DeepSeek's implementation predicts four tokens simultaneously, using a "look-ahead" mechanism during both training and inference, to make parallel predictions about the next token. Their technical report describes a causal masking approach that maintains proper sequence dependencies.
When combined with their MLA architecture and auxiliary-loss-free MoE, DeepSeek reports:
2.5x speedup in text generation
40% reduction in training time
Quality metrics comparable to sequential prediction
Once again - there's prior art for this technique. Most recently, Meta FAIR published research showing up to 3x speedups through multi-token prediction while improving model quality.13
Recap
I hope what's clear by now is that DeepSeek's innovations in no way seem to be secret research or state-sponsored voodoo. These implementations have been validated in prior work by Western sovereigns and open research teams. They're just the first to combine them.
When combined, the efficiency gains compound tremendously:
Memory: 93.3% reduction through MLA, while extended context windows by 32x
Training: 71% reduction in compute costs, achieved with just $5.6M total training budget
Throughput: Up to 5.76x improvement during inference
Performance: Matches or exceeds models 2-3.5x larger on standard benchmarks
Culminating in a state-of-the-art model trained on $5.6M worth of compute, compared to $78M (GPT-4), over $100M (LLaMa 3 405B), and $191M (Google Gemini Ultra).
The Sovereign AI Trap
These efficiency breakthroughs expose a critical flaw in the sovereign AI strategy: what if bigger isn't actually better?
Thus far, sovereigns' approach to AI development has followed a predictable pattern:
Raise massive amounts of capital
Build increasingly large models behind closed doors
Maintain strict control over architecture and training data
Rely on raw compute power as a competitive moat
Where possible, use regulatory capture to strengthen their position14151617
Wind back the clock a year to February 2024: OpenAI's Sam Altman was attempting to raise $7T (TRILLION) to reshape the global semiconductor industry, arguing he needed unheard of chip fabrication investments meet AI compute demands18, no doubt influenced by OpenAI's massive cost basis19.
Sam's concerns weren't exactly unfounded at the time, but DeepSeek's reported cost advantages have now cast significant doubt on the sticker price he was quoting.
To put it in perspective, The Information estimated that for 2024, OpenAI spent up to $6B on compute-related costs against annual revenues of $3.5 - $4.5B. If the numbers we've heard are true, that would mean OpenAI is spending more than 2 DeepSeek-R1 training runs per day on compute costs.
Now it's at this point that skeptics would assert one of three things:
DeepSeek had inherent cost advantages as a 'follower' rather than an 'innovator.'
Those aren't apples to apples comparisons on compute-per-dollar efficiency.
You fool, you absolute buffoon, don't you understand? Sovereigns can simply replicate DeepSeek's efficiency gains and deploy them across their larger compute footprints.
To which I say: fair. Most articles I've read up to now stop at this point. Let's dig deeper.
1. Second-mover advantages
Truth be told, followers do have an advantage - Epoch AI has pointed out the physical compute required to achieve a given level of performance drops by 3x every year, so for a 10x training cost reduction, about a 14 month lag time seems appropriate20. Except DeepSeek-V3 caught up to Llama 3.1 405B, the prior OSS state of the art, in just 5 months - less than half that estimate. That's a significant bucking of the trend.
Further still, open-source models tend to lag their closed source competitors by about one year. The going assumption is closed-source research labs have access to more compute and data than their open source counterparts (Meta's contributions notwithstanding21), and it takes time to replicate those models in the open.

But even OpenAI's o1, considered a breakthrough in reasoning capabilities and a potential "path forward" beyond traditional scaling limitations2223, wasn't immune to the DeepSeek effect. Their open-source reasoning model, DeepSeek-R1, met or surpassed o1's performance just 4 months later.
So yes, DeepSeek enjoyed the fruits of second-mover advantages as Meta, X, Cohere, and others have. But where all the others took about a year to catch up, DeepSeek did it in a third of the time.
2. Compute-per-dollar efficiency
Given the effective compute efficiency curves I just mentioned, we know training costs become cheaper overtime for a given architecture and training recipe. So it's unfair to compare GPT-4 and Gemini Ultra costs _at that time_ to DeepSeek's today.
Fortunately, @arankomatsuzaki and @ldjconfirmed [have done the work for us](https://x.com/arankomatsuzaki/status/1884676245922934788?s=46). Here's the estimated training costs for a benchmark set in 2025 prices:

For the curious, the researchers provide an online calculator for you to run the numbers yourself.24
"Ah," you might say, "but DeepSeek's model family only has a 6x cost advantage over GPT-4 and Claude-3.5!" And again, I say: fair. But that's not the point. OpenAI and Anthropic have already booked the capital expenditures required to train those models - the money is out the door. And for the upcoming 100K H100 colossal language models, those costs are expected to be higher, astronomically higher.
What I'm saying is, the apples-to-apples appeal may be important academically, but I only minored, not majored, in economics. I care a lot more about the all-in cost.
3. Compute economies of scale
Sovereigns absolutely could replicate V3 and R1's algorithmic improvements in their own systems, and I hope they do, users would be better off for it. But they've already spent the money they needed to scale up their inference businesses and training clusters, and need to recoup their capex somehow.
Under normal circumstances, that might mean artificially higher API prices in the initial months post-rollout, which 'magically' come down as equivalent caliber models diffuse into the market.
DeepSeek may have just nuked that chance, leaving OpenAI (and others) holding the bag. At the time of writing, OpenAI is charging $15 / 1M input tokens for o1 access, and DeepSeek-R1 is charging $0.55 / 1M tokens.
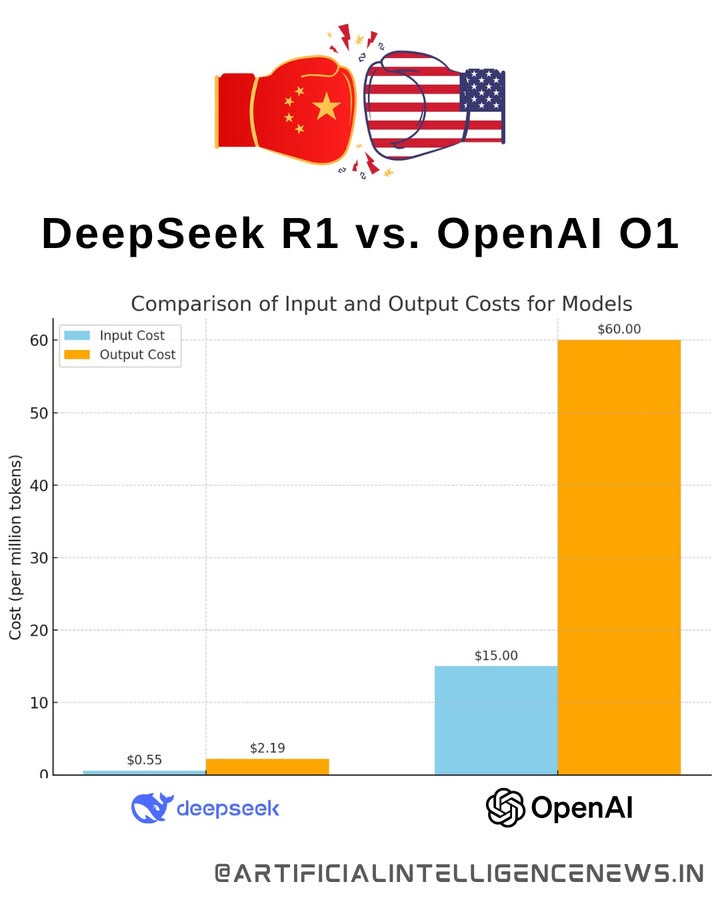
Expect these margins to narrow soon, but sovereigns need to differentiate themselves and fast.
Recap
Knowing what we know now, it's worth re-examining OpenAI's trillion-dollar chip ambitions. Were they driven purely by market demand, to more democratically diffuse access to intelligence? Or were they solidifying a competitive moat through artificial scarcity, maintaining a leading edge through anti-competitive means?
Wherever OpenAI is on the spectrum, DeepSeek severely upset the apple cart. Sovereigns (and their backers) have gone all-in on an extravagantly expensive strategy, and may have cornered themselves into a trap. Without serious differentiation, their lead may not last long enough to recoup their capex. That threatens the multi-billion dollar ecosystem of research labs, hyperscalers, energy companies, venture capital, and national industrial policies that are betting it all on a centralized, compute-intensive future.25
2. The Efficiency Paradox
This was a major shock to the markets, which in the short term clearly wondered whether low-cost compute would nerf demand for high-performance chips and components. Fortunately, as a general-purpose technology becomes more efficient and accessible, aggregate demand increases as the market finds more uses for it. The commoditization of intelligence will likely lead to accelerated adoption across multiple industries, rather than a market contraction.
Immediate Fallout
This faster-than-expected moat erosion has incumbents scrambling to figure out a response26, and the markets took notice.27 Headlines screamed about the bursting of the hype bubble, as investors processed what DeepSeek's efficiency gains might mean for the ecosystem.28
NVIDIA, the primary beneficiary of sovereigns' compute addiction, booked the biggest one-day loss in history - close to $593B in market cap, a 17% hit29. Semiconductor and hardware component stocks like Broadcom, Marvell, Micron, and others also took double-digit hits.
More surprising to some were the unexpected beneficiaries. Apple, criticized for its conservativism (and borderline braindead Apple Intelligence rollout), saw its stock price actually appreciate by a few points. While surprising to some, Apple has been pursuing a very different strategy, emphasizing edge inference and custom silicon for their own devices. To Apple, it really doesn't matter what models people prefer to use - what matters is where the models live and run.
signüll on twitter had a great breakdown:

We're only a few days out from the Monday correction, but I expect Apple will continue to sit pretty for a while longer, thanks to an economic principle that's picked up again in online meme circles - Jevons Paradox.
Jevons Paradox
In 1865, English economist William Stanley Jevons observed that across a wide range of industries, the increased efficiency of coal use led to its increased consumption. The less it cost to use, the more uses people found for it, roughly maintaining or growing aggregate demand.
That's it. It's not complicated. There, saved you a lengthy twitter thread.

Economists have observed the same phenomenon in hybrid engines and driving distances, expanded highways and traffic times, bandwidth costs and internet usage, and many other examples.30
Now contemporaries are applying the same logic to intelligence as a commodity - the more we have, the more we want. If true, what tailwinds are contributing to an accelerating intelligence' diffusion?3132.
Tailwinds for intelligence efficiency gains
First, let's look at the data. Epoch AI's analysis argues that, in terms of raw resources required to achieve a given level of performance, 2/3rds of the gains are attributable to more scale (chips), and 1/3rd to algorithmic progress.

It's either better algorithms, more hardware, or better hardware. And while up to now we've focused mostly on training costs (building intelligence), the much larger category of spend is actually inference costs (using intelligence).
1. Better algorithms
Foundation model developers that can mimic sovereigns' performance capabilities at a fraction of the price are well-positioned, as businesses question the sticker prices they've been sold up to now. Fastino is one such company, whose novel architecture is so ridiculously efficient that it yields 2,000+ tokens per second on a CPU. (full disclosure, I'm an early investor).
Cartesia is another example that use efficient alternative architectures to meet or eclipse dense transformers' performance on various tasks, with the company claiming its state-space models (SSM) are efficient enough to run just about anywhere.33 Coincidentally, SSMs use similar memory compression techniques to DeepSeek's MLA, summarizing context to enable efficient, long-range memory.
2. Better hardware
The same logic applies to semiconductor efficiency gains with companies like Positron, which I'm also an investor in. Assuming token generation throughput parity (and model compatibility), performance per watt improvements are likely to yield increased demand as a multiple over the NVIDIA baseline.
Datacenters will need to expand to keep up with compute demand, but newer Blackwell chips from NVIDIA are expected to cost more, not less, in opex, due to critical design decisions that raise electricity consumption and cooling needs.34 With downward pressure on compute costs, and physical limits on electricity consumption per rack, datacenter customers have to improve margins where possible.
3. Efficient energy systems
To get around these problems, datacenters can do quite a lot in optimizing their operations before making any chip decisions. They have physical limits they have to abide by. Options vary for new builds vs retrofits, but some contributors I'm seeing include:
Liquid immersion cooling. Highly efficient method of cooling datacenter equipment. Strictly on a square-foot basis, reduces datacenter footprints by up to 10x, with the input costs being the container and the coolant, that can upgrade the power usage effectiveness (PUE) of datacenters from ~1.55 down to as low as 1.05
Datacenter power and energy management software. This market is relatively immature, and most DCs have been caught flat-footed as they've mostly rolled their own custom software up to now. It hasn't been battle-tested for intense AI workloads. Companies like CentralAxis that can provide mature, scalable, and user-friendly solutions are well-positioned.
Natural gas suppliers. Everyone in my circles won't stop talking about nuclear energy, which I'm all for and excited about, but the demand exists NOW and we don't yet have nuclear capacity to absorb it. Fortunately, existing natural gas suppliers all over the Permian are already raking it in with datacenter end-customers, and I expect that only to increase overtime.
4. Edge inference and model commoditization
Finally, as we saw with Apple's stock performance, companies positioning themselves for a world of efficient, widely-available models - whether through edge computing, optimization layers, or deployment platforms - are likely to benefit from increased AI adoption even as sovereign margins get compressed. Model commoditization, rather than artificial scarcity, is a more anti-fragile bet.
Chip Market Implications
With all that said, obviously more chips to use means greater capacity for intelligence diffusion. But as for specific winners here, the hardware story is more nuanced.
1. Hardware baselines
NVIDIA remains the only serious game in town for high-performance training hardware, though with a twist I didn't expect. Historically, their chips configurations have been inefficiently utilized in inference, using only about 30% of their memory bandwidth at peak35.

But their new GB300 chip seems purpose-built for reasoning models, which require more memory bandwidth for longer chains of thought. If reasoning models like R1 virally spread at DeepSeek prices, inference demand may actually spur even more demand for NVIDIA's latest chips.36
2. Inference optimization
Aside from performance-per-watt optimization via Positron, customers may want to optimize against speed and latency above all else. Hyper-fast inference chips from companies like Groq and Cerebras are valuable... but need to make economic sense on a total cost of ownership basis. Groq's design decisions for its LPU chips optimize for speed, but severely sacrifice memory capacity, requiring 10 racks to deploy a 70B model that would otherwise fit on a single GPU373839.
The question remains whether that strategy makes sense for diffusing into the entire datacenter market, or if the only path forward is vertical integration, which could be another version of a sovereign trap.40
3. Infra software
The infrastructure software layer is where we start to see clearer winners and losers. NVIDIA's years of investment in CUDA has created an ecosystem and user experience that competitors struggle to match. AMD's story is instructive - despite MI300X being on par with (or better than) NVIDIA's H100/H200 line, AMD's ROCm dogwater software stack prevents them from realizing those hardware advantages, and they've made no successful effort in the past year plus to close that gap.4142
Having said that, it's worth noting that DeepSeek did collaborate with AMD in developing DeepSeek-V3, which may be a soft endorsement of their Instinct chip line and software stack.43
Basically, what I'm saying is that a rising tide does not lift all boats here. Some boats have holes in them. They need to be patched up, and until then exist on an entirely different demand curve.
The Real Paradox
I'm crudely bisecting the AI market into 2 sets of players: those accelerating its diffusion, and those rent-seeking through artificial scarcity.
DeepSeek's breakthrough demonstrated that the moats closed-source model had are not as defensible as sovereigns believed. They may yet adapt by adopting these efficiency gains, and closed-source models do still dominate enterprise workflows for the time being. But DeepSeek's cost trajectory suggests a reckoning is inevitable. The market's reaction shows that investors are starting to recognize this new reality.
The real efficiency paradox is this: do sovereigns have the cojones to disrupt themselves? Or will they cry foul and double down on protectionism?
3. The Technopolitical Reckoning
American Sovereign Responses
Predictably, American stakeholders have responded with a mix of hostility, defensiveness, and existential ruminating. I mean, it's hundreds of billions of dollars on the line here.
"They cheated"
OpenAI directly accused DeepSeek of using OpenAI models to train their own, by training based on outputs from ChatGPT, which would give DeepSeek an unfair advantage. No evidence has actually be presented yet, just conjecture, and the reactions from Twitter have been... less than sympathetic.

"Actually, we hate open source"
Meanwhile, venture capitalists with large stakes in American AI companies are reportedly in "crisis mode", as this breakthrough threatens the competitive advantage of their portfolio companies. Some are questioning whether models should be allowed to be open-sourced at all... which is a ridiculous take.
Alleged export control violations
To tie this all together, the "DeepSeek is a Chinese psyop" conspiracy (disclosure: the tweet author's dad has a large stake in OpenAI) only works if the CCP secretly granted DeepSeek access to advanced chips China procured through illicit means.
Alexandr Wang, CEO of Scale AI, made one such (unsubstantiated) claim, that DeepSeek has access to 50,000 advanced AI chips that it shouldn't have, given US export controls. Dario Amodei (Anthropic) and Elon Musk have also been supporters of this theory.
I'm not naïve - there are certainly shady dealings happening in Southeast Asia to evade export controls.44 That said, in true open-source spirit, DeepSeek released its complete training recipe for its models, and HuggingFace is already hard at work rebuilding it from scratch... so if it truly would take 50,000 H100s to build it, we'll all know soon enough anyway.45
If it were actually a conspiracy, that would be like handing over a smoking gun. A couple weeks of market confusion, maybe, but no lasting damage. Just a really dumb prank.
Altogether, these gripes betray a deep misunderstanding of how open source research works. I provided rich citations for DeepSeek's architectural decisions and training recipes explicitly to point out that _none of these techniques are new or unheard of_. This is just the first time someone has put them all together. It's a Sputnik Moment, sure... but as far as China's concerned, their own Sputnik Moment was two years ago when ChatGPT was released.
The China takes
In contrast, the response from Chinese media, AI executives, and netizens has been overwhelmingly positive, tinged with national pride and interesting fanart. I'm especially grateful to Jordan Schneider and his team at ChinaTalk (longtime listener) for collecting some of the best quotes from first-party sources.46
China Daily declared, "For a Chinese LLM, it's a historical moment to surpass ChatGPT in the US."47 Daily Economic News echoed this sentiment, stating, "Silicon Valley Shocked! Chinese AI Dominates Foreign Media, AI Experts Say: 'It Has Caught Up with the U.S.!'"48
Feng Ji 冯骥, founder of Game Science (the studio behind Black Myth: Wukong), called DeepSeek "a scientific and technological achievement that shapes our national destiny (国运)."49
Zhou Hongyi, Chairperson of Qihoo 360, told Jiemian News that DeepSeek will be a key player in the "Chinese Large-Model Technology Avengers Team" to counter U.S. AI dominance.50)

A closed-door session between Shixiang 拾象, a VC spun out from Sequoia China, and dozens of AI researchers, investors, and insiders provides an even richer view on DeepSeek's market entry.
Key takeaways from the discussion include:
**Celebrating efficiency as a source of resilience.**
"How Chinese large-model teams use less computing power to produce results, thereby having some definite resilience — or even doing better — might end up being how the US-China AI landscape plays out in the future."
**Addressing the efficiency paradox head-on.**
"In the long-run, questions about computing power will remain. Demand for compute remains strong and no company has enough."
**Open source controls the margins of the whole market; the US discovered that China is not two years behind, but 3 to 9 months.**
"If the capabilities of open-source and closed-source models do not differ greatly, then this presents a big challenge for closed source."
**This, plus the lack of a good business model for AI labs, heightens the commoditization risk.**
"The business model of AI labs in the United States is not good either. AI does not have a good business model today and will require viable solutions in the future. Liang Wenfeng is ambitious; DeepSeek does not care about the model and is just heading towards AGI."
**Differentiation has to therefore come from vision, not from technology scarcity.**
"China is still replicating technical solutions; reasoning was proposed by OpenAI in o1, so the next gap between various AI labs will be about who can propose the next reasoning. Infinite-length reasoning might be one vision. The core difference between different AI labs’ models lies not in technology, but in what each lab’s next vision is. After all, vision matters more than technology."
4. The End of the Sovereign Era?
To put it bluntly, "the global diffusion of AI is now irreversible" (full translation here).
HuggingFace is already hard at work replicating R1 to prove, without a shadow of a doubt, its validity
Community researchers are sharing resources for running full, undistilled versions of R1 on prosumer hardware that is highly unlikely to fall into an export ban
The nail seems to be in the coffin for the sovereigns' initial strategy. Don't worry, they've got big treasuries and have time to adapt, but the model is not the product, and never has been. That said, they've been inefficiently burning capital at a rapid clip, and will likely use the market moment to double-down with additional funding.
The stark contrast between the American and Chinese responses to DeepSeek's breakthrough reveals deep geopolitical fault lines we already knew were there. Americans responded with skepticism and allegations of foul play, while the Chinese AI community (and frankly, a lot of the open source community) celebrated DeepSeek's achievements as a validation of their own strategic vision.
Its exciting to see open source provide such a strong counter to power ossification, and I strongly believe this will be a huge boon for boosting AI supply chains and markets in the aggregate. Efficient training techniques, edge inference, and energy-efficient datacenters all point to model commoditization as an inevitability, and these efficiency gains will drive demand to new heights.
Critics might argue my optimism underplays real moats that sovereigns possess: proprietary data, regulatory capture, or ecosystem lock-in. These are valid concerns. But I still believe efficiency and community momentum will outweigh them overtime.
In the new era of AI diffusion, I believe winners will be those who embrace intelligence' commoditization and find ways to create value on top of it. If we get this right, we can uplift the entire economy... rather than a few magnificent slices of it.
This last point is important to track, as it strongly influences sovereign decision-making. OpenAI recently appointed former NSA director Paul Nakasone to its board, while Mistral AI has benefited from an exceptionally close relationship with the French government during EU AI Act negotiations. Even Cohere received $240M from the Canadian government to build out AI compute capacity.

