

Silicon Vanguard: Ranking China's Domestic Chip Leaders
meet the hardware powering its sovereign AI ecosystem

When I first started on this project, it was mostly just scratch notes from in-country conversations with Chinese semiconductor experts and investors meant to inform our hardware theses at Edgerunner Ventures. But this kind of took on a life of its own, and I have other things I’d like to write on… so publishing it below now in full.
I’m also releasing v0.1 of the ”Silicon Vanguard” dataset, which powers the bulk of this analysis. Chinese chip companies aren’t as forthcoming about individual unit specs, so it’s difficult to find performance data from reputable sources. I decided to compile my own from securities filings, archived company pages, and other firsthand sources, and I will be adding more to it over time.
This is my longest post yet - 13,000 words - so fair warning, instead of just diving in, I’d recommend the following order:
POLICYMAKERS / BIG PICTURE FOLKS:
TECH-FORWARD ANALYSTS:
While the content itself is written by me, this was a valuable stress-test on modern LLM limitations for deep-tech, bilingual industry analyses, revealing fault lines on citations and hallucinations. Western model providers almost never use firsthand Chinese-language sources, but handle mixed-language PDFs okay. DeepSeek, Kimi K2, and Chinese models are way better at sourcing, but suffer from more serious hallucinations in long context windows, requiring a lot of triple-checking and filter-maxxing. To this end, if anything is inaccurate, please comment with other firsthand sources! Will edit and gladly attribute the correction.
Lastly, my friend Lesley Gao (author of Shear Force) was incredibly helpful in sourcing additional materials to pad out financials and leadership information, as well as contributing to general takeaways. Her recent post, How a $1 Lighter Defied Inflation for 20 Years, is an excellent primer to Chinese industrial clusters, and as a framework carries serious relevance for all kinds of industrial policymaking.
Introduction
If you ask the question “how far behind is China on leading edge semiconductors,” you’ll get as many different answers as the number of people you ask. 20 years1, 10 years2, 5 years3, 2 years.4 If you ask “who will become China’s NVIDIA,” you may most commonly hear “Huawei,” or more recently “Cambricon.”5
To me, all variants of these questions are unsatisfactory. Focusing solely on the immediate, visible events - the “leading edge” - overlooks underlying systems that generate and sustain technoeconomic momentum. After all, the Titanic didn’t strike the ice above the surface… it struck the entire iceberg underneath. This is why technological change often feels gradual, then all of a sudden.
Additionally, while most domestic chips lag foreign competitors in raw performance, obsessing over isolated stats ignores an objectively rapid pace of development. Their performance on energy-compute metrics, I believe, are more germane to questions on sovereign AI.
A more nuanced understanding of China’s chip ecosystem is therefore warranted.
In this post, I’ll pull back the veil on 16 companies we’re tracking in this space, and attempt to make sense of their relative positioning in the market. These breakouts are finding new ways to bypass tech bottlenecks with heterogeneous approaches, deep cross-sector collaborations, and novel design paradigms. There are also clear losers which highlight limits to a state-led innovation ideology. Truly there are dozens of companies worth mentioning, but only a handful have made meaningful contributions to the country’s sovereign chip ecosystem thus far.
To be clear, we’re focusing solely on the fabless accelerator (GPU and ASIC) chip designers of today. We’ll save CPUs, FPGAs, and memory chip IDMs like SMIC, CXMT, and YMTC - all critical parts of the value chain - for a future deep-dive.
It’s fair to argue this analysis is incomplete without fully assessing domestic ability to reliably fabricate these chips (e.g. SMIC, YMTC, CXMT), but as we’ll see, even if you hold domestic yields frozen at current levels, you have to admit designers have made considerable strides along the tech tree.
Executive Summary
I’ll summarize the findings of this analysis up front, and lay out its implications for American technologists and policymakers. Read on for fuller details on individual companies, performance specs, and qualitative measurements.
Takeaways
First, while U.S. entity listings may have had a deleterious effect on some individual first movers (e.g. Biren, Moore Threads), this strategy undoubtedly catalyzed domestic chip and software innovations bypassing one-off tech bans. As an example, this month Huawei HiSilicon plans to open-source its Unified Cache Manager (UCM), an AI inference acceleration toolkit which shards model memory workloads across different memory types (HBM, DRAM, even SSDs), reducing latency by up to 90% and improving system throughput by up to 22x.6 This would significantly blunt the impact of HBM restrictions on sanctioned entities, which experts agree is a critical bottleneck for domestic accelerators.7
Second, the domestic ecosystem is converging on model, hardware, and precision standards meant to establish “good enough” performance for large-scale deployments. DeepSeek has also announced its support for UE8M0 FP8 precision as a performance standard for domestic chips, and chipmakers are proclaiming FP8 support for their newest SKUs (Cambricon 思元690, Enflame 邃思L6008, SOPHGO SC11-FP3009). CAICT recently began issuing “AI Chip and Large Model Adaptation Test Certificates” to chipmakers (Moore Threads, SOPHGO) that have demonstrated “passable” inference performance for full-blooded DeepSeek R1 671B. This third-party baseline establishes acceptability thresholds for performance and energy efficiency, and provides clarity to buyers and sellers in the procurement process for multi-million dollar chip contracts.
Third, hardware-specific investments are bearing fruit in sparse computing and in-memory / near-memory (PIM / NDP) designs. Moffett AI’s first-gen chips have already out-performed the NVIDIA H100 in MLPerf Inference benchmarks, achieving >1.6x performance throughput at a ~3x smaller energy footprint, yielding ~5x greater tokens / joule in single-card and supernode environments.10 Continued advancements in sparsity, analog computing, and heterogeneous computing techniques are improving energy-compute yields and reducing total cost of ownership.
Finally, the last pillar may be NVIDIA’s software moat (CUDA), though this too may be about to crack. While CUDA (and even AMD’s ROCm) are still preferred by the majority of Chinese AI engineers, leading chipmakers (Baidu Kunlunxin, Moore Threads, MetaX, Enflame) have announced top-level priorities to ensure full CUDA compatibility for their newest chips, and vendor-specific transcompilers are seeing remarkable improvements in CUDA translation performance (Cambricon’s Qimeng-XPiler yielding 95%+ accuracy and <5 hours debugging time)11. This is likely a greater threat to CUDA dominance than a head-to-head CUDA vs. CANN open-source developer battle.
In sum, we’re witnessing an inflection point in domestic Chinese chip capabilities. Despite lagging behind trailing-edge NVIDIA chips, domestic hardware is evolving beyond mere sufficiency for powering a sovereign AI ecosystem - it may soon be sufficient to begin exporting the Chinese AI stack.
Implications
In case I haven’t made this abundantly clear… the horse has left the barn. Continued attempts to control, deny, or retard domestic Chinese progress will only accelerate this now inevitable transition. Cold War-era technology restrictions are completely at odds with how international developer ecosystems function, and in the modern era create antithetical outcomes to their stated objective.
Senior AI Policy Advisor Sriram Krishnan articulates this reality well, stating the U.S. needs to maximize developer market share of the “American AI Stack” - the models, chips, and software being used to train and run them. It’s a classic developer flywheel.12
We are already in the first bouts of this “AI Stack” competition. Here in the Valley, most developers and startups I know are using Chinese models in some capacity (Martin Casado of a16z estimates 80%)13. And who can blame them - these models are open-source, meet or exceed American model quality, and are 10x-30x cheaper when hosting for inference.
Meanwhile, domestic first-movers OpenAI14 and Anthropic15 are implementing restrictions to manage inference costs, nerfing performance, throughput, and output quality in the process. This is a fast track to AI platform decay - or “enshittification” (平台屎化, píngtái shǐ huà) - and discourages developers from building on volatile infrastructure.
This reality demands a strategic recalibration. While a holistic approach to building the American AI Stack is a starting point, evidence from China’s Silicon Vanguard demonstrates that energy-compute optimization is becoming the decisive factor in at-scale deployment of AI systems… and will come to define sovereignty in the new world order.
Containment is no longer an option. The only option is to compete.
The Players
This won’t be an all-inclusive list. There’s a lot of investment dollars going into this sector as China rapidly builds up its domestic semiconductor manufacturing and design muscle.
Here are the names of the 16 entities we’ll be covering.

Below are other logic chip designers primarily building CPUs and FPGAs. They aren’t the subject of this post, but we’re tracking them nonetheless.

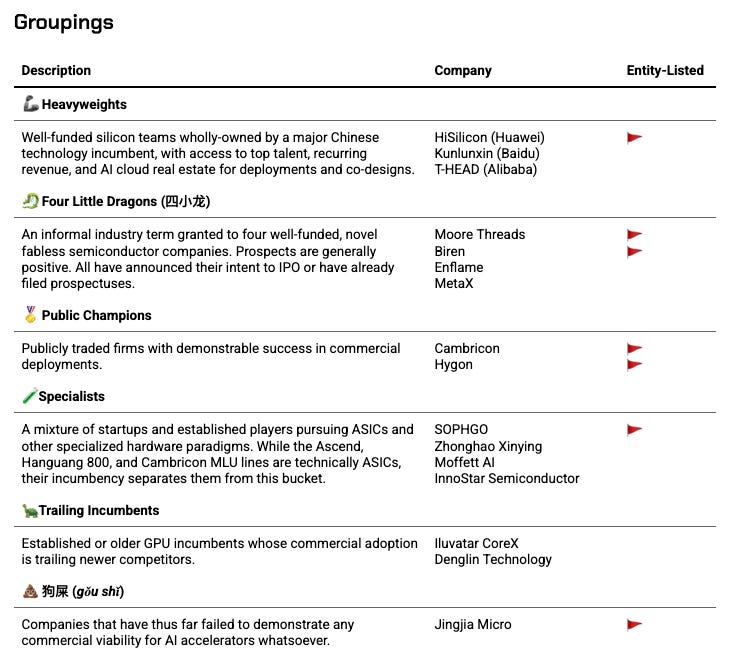
Groupings
We categorize these 16 players out into 6 groups based on their stages of development, adoption, and inherent competitive advantages.
Tier List
Since most people are going to skip to this section anyway, I’ll tee up my domestic tier list for the players we’ve evaluated. This was inspired by Nathan Lambert in his China Research Lab breakdown, but is by no means an authoritative declaration - it’s subjective and shouldn’t be taken too seriously.
To be clear: this is strictly a domestic tier list. We’ll include comparisons to China-available NVIDIA and AMD chips later on, but including them here would pollute the purpose of the exercise.

S through D tiers (along with the 狗屎 bottom tier) are ranked based on a rubric assessing company performance across 5 dimensions: product, leadership, developer adoption, commercial adoption, and strategic backing.
A separate tier, “Edgerunner,” is reserved for players pursuing novel hardware designs that effectively bypass systemic energy-compute bottlenecks. They may have either limited or unavailable information on commercial deployments. This is not an ordinal ranking per se, but a callout that we should pay close attention to progress on these design paradigms.
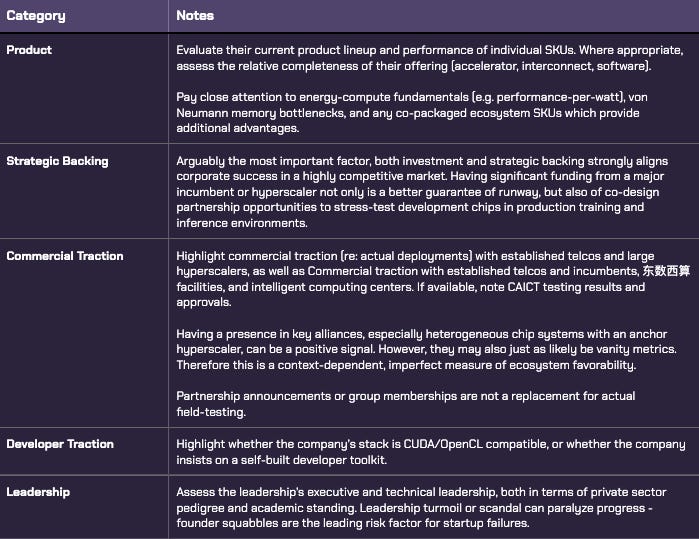
Ranking Rubric
The analyses sections go into plenty of detail on evaluations - the rubric is here for reference.
Company Profiles
Taxonomy Primer
Skip if you’re already familiar.
In semiconductor coverage, a bunch of acronyms can get confusing. It also doesn’t help when technical and marketing terms are often conflated (e.g. Google “TPU” brand, SOPHGO’s TPUs, and Zhonghao Xinying’s “GPTPUs”). This confuses retail investors, policymakers, and seasoned analysts alike.
To keep it simple, here’s a primer for logic chip taxonomy, as well as where each of our companies fit in that schema. If the entity designs chips in multiple categories, it’s mentioned in each.
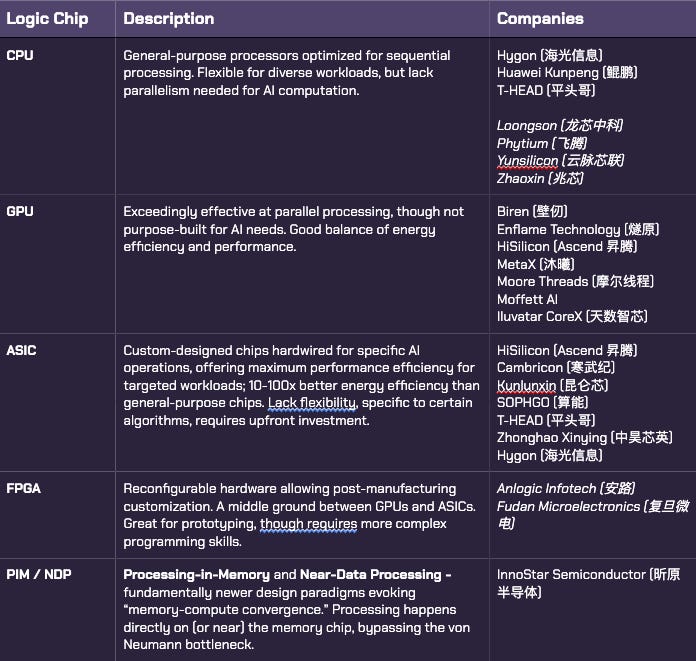
Italicized names are not covered in this post.
As a general rule of thumb, this list is in order of generalizability and energy efficiency for AI workloads. GPUs are general-purpose and strike a good balance between performance and efficiency, but are outclassed by ASICs on energy-compute terms. ASICs have slower iteration times due to hardware life cycles and a more limited customer base, but are often the logic chip of choice for large hyperscalers who are their own customers. Lastly, PIM / NDP chips are the most energy-efficient logic chips by orders of magnitude, but are still in an experimental stage of development. Data on their performance in production environments is somewhat limited.
🦾 Heavyweights
Well-funded silicon teams wholly-owned by a major Chinese technology incumbent, with access to top talent, recurring revenue, and AI cloud real estate for deployments and co-designs. Strategy is generally to win at rack-scale, not at card-scale - custom interconnects a major boon.
Huawei HiSilicon (华为海思)

1991 | hisilicon.com | Private | Entity Listed 🚩
China’s most vertically integrated NVIDIA alternative: Da Vinci core-based 910A/B/C parts bound into Atlas boards/servers and rack-scale CloudMatrix systems, with CANN software and optical backplanes. The 910C centers on dual-chiplet packaging (~53 B transistors, ~64 AI cores) with 3D die-to-die fabric and HBM3, serving as the building block for CloudMatrix 384 across 16 racks.
Strategy is “win at rack scale,” trading device-level peak for throughput-per-rack and supply security; pricing (≈¥110k for 910B; ≈¥180–200k for 910C) underscores the TCO pitch versus scarce H100/H200. Adoption is broad across state-linked telcos, finance, and internet platforms; some 910C deliveries push into late-2025 as capacity ramps.
T-HEAD / Alibaba (平头哥)

2018 | t-head.cn | Private
Alibaba’s chip arm merging C-SKY + DAMO chip team: open-source Xuantie RISC-V cores on one flank, Hanguang NPUs and Yitian CPUs on the other. Hanguang 800 (12 nm; large on-chip SRAM, flexible precision) was architected as a high-efficiency inference engine for Alibaba workloads (images/video, recommendation, “City Brain”). Patent surveys point to a new phase of chiplets and dataflow-centric fabrics with adaptive tiling and aggressive mixed precision. chiplet-based, dataflow-centric fabrics with adaptive tiling and aggressive mixed precision.
Adoption is primarily internal/partner-cloud: Panjiu/HPN7.0 fabric interconnects thousands → hundreds-of-thousands of accelerators; migrations from DCN+ to HPN show material end-to-end training gains. ALink aims to NVLink-like scale for both international and domestic chips - a vertically integrated path to cost/latency control rather than chasing peak single-card specs.
Kunlunxin / Baidu (昆仑芯)

2011; spun-out 2019 | kunlunxin.com | Private
Baidu-born XPU line integrated with Baidu Cloud + PaddlePaddle: 1st-gen Samsung 14 nm shipped widely; Kunlun II (7 nm, XPU-R) expanded the base; P800 (XPU-P) targets LLM training and 8-bit inference with rack-scale 超节点 cabinets. Advantage is tight alignment with Baidu’s software and services.
Adoption proof points include China Merchants Bank’s AI chip project (P800 backing full-fat Qwen/DeepSeek variants on 8-card nodes and clusters) and Baidu’s own 万卡→三万卡 P800 fleet growth in-cloud.
🐉 Four Little Dragons (四小龙)
An informal industry term granted to four well-funded, novel fabless semiconductor companies. Prospects are generally positive. All have announced their intent to IPO or have already filed prospectuses.
Enflame (燧原科技)

2018 | enflame-tech.com | Private
Shanghai ASIC house led by AMD alumni (Zhao Lidong, Zhang Yalin), optimized for scale-out systems over single-chip hero numbers. Tencent is both anchor investor and proving ground; Big Fund participation adds patient capital. 2024–25 pushed mass inference (S60) while refreshing training (L600 训推一体 with higher on-package memory/interconnect).
Traction is real: ~70k S60 units shipped; the Gansu Qingyang 10,016-card S60 cluster under 东数西算 is a marquee win; earlier provincial clusters (e.g., Yichang) and wide Tencent workload coverage bolster credibility. The software ecosystem (“驭算/鉴算”) still trails CUDA, but the company is investing to close op coverage and porting costs. WAIC 2025 showcased “DeepSeek-ready” all-in-ones for R1-671B, doubling down on visible, workload-level validation.
Moore Threads (摩尔线程)

2020 | mthreads.com | Private (IPO Prospectus) | Entity Listed 🚩
Beijing fabless GPU vendor founded by ex-NVIDIA China GM Zhang Jianzhong; heavily backed (ByteDance, Tencent, China Mobile equity arm, Lenovo Capital) and fast-iterating across 苏堤→春晓→曲院 with the MUSA stack; shifted from TSMC to SMIC post-Entity List.
Adoption signal is improving: CAICT validated the MTT S4000 for large-model inference; deployments span Kuaishou (1,000-GPU cluster), the big three telcos, and university/energy partners. Datacenter SKUs (S3000/S4000) anchor B2B, while the E300 edge module (AB100 AI SoC, ~50 TOPS INT8) shows consumer/edge ambition. Performance lags NVIDIA’s top end but distribution, capital, and ecosystem deals give it staying power domestically.
MetaX (沐曦集成电路)

2020 | metax-tech.com | Private (IPO Prospectus)
Shanghai GPGPU startup (AMD-veteran founding team) with three series—曦思 N (inference), 曦云 C (training/compute), 曦彩 G (graphics)—plus CUDA-like MXMACA and MetaXLink interconnect. STAR Market IPO prospectus accepted 2025-06-30; >25k units shipped; next-gen dual-chiplet C600 touts 144 GB HBM3e.
Commercial motion leans on operator/provincial compute platforms and national distributors: disclosed multi-billion-RMB orders via integrators, Lingang partnerships, and “千卡级” clusters. Earlier parts relied on overseas HBM/foundry; newer N300/C600 are billed as domestic supply chain supported (“基于国产供应链”) signaling a risk-mitigation pivot while keeping cost-right inference as the spearhead.
Biren (壁仞)

2019 | birentech.com | Private | Entity Listed 🚩
Early bright star in domestic semiconductor design, Shanghai-based player built around the BR100 7nm chip with a star lineup of ex-NVIDIA/AMD/Huawei/Alibaba talent; later leadership churn followed Entity List actions and a pivot from TSMC to SMIC (N+2) with simplified derivatives (BiLi 106/110/166). Software stack (BIRENSUPA) is AI-first, not consumer graphics, and does not seem CUDA-friendly.
Commercially, Biren is lagging newer dragons, but has nonetheless landed state-linked telcos/clouds (China Mobile/Telecom), SenseTime, State Grid, and Shanghai AI Lab (1,000-GPU cluster). Newer liquid-cooled OAM lines and the “LightSphere X” photonic SuperNode (with Xizhi & ZTE) target density/efficiency at 2,000-GPU scale; first stop is the Shanghai INESA Intelligent Computing Center.
🏅 Public Champions
Publicly traded firms with considerable success in commercial deployments.
Cambricon (寒武纪)

2016 | cambricon.com | 688256.SH | Entity Listed 🚩
CAS/USTC child prodigies spun early domestic accelerator research (DianNao) into a commercial ASIC line; after early highs (Kirin 970 era) and a slump (Entity List, lost smartphone socket), the Siyuan 590 (domestic 7 nm) catalyzed a resurgence with A100-class training in some metrics. H1’25 revenue spiked ($400M) but is highly concentrated (top-5 ≈95%, one ≈79%—rumored ByteDance).
Cambricon is again relevant in training-class deployments (Siyuan 590 now, 690 next), fueled by heavy R&D (≈¥1.07 B in 2024, ~91% of revenue). Concentration risk is real, but the technical IP, government alignment, and renewed customer pull have shifted the narrative from “fallen star” to “second act.”
Hygon (海光信息)

2014 | hygon.cn | 688041.SH | Entity Listed 🚩
Originally established as a joint-venture between AMD, Chengdu Haiguang Microelectronics, and Chengu Haiguang Integrated Circuit Design. Best known for CPUs, Hygon has been reorganizing into accelerators with DCU-branded GPGPU-like parts (CUDA-compatible environment). DCU8100 accelerator reports parity with A100/MI100 in some precisions. A major 2025 move was the announced merger with Sugon (曙光) to tighten the HPC stack.
Current accelerator push seems to be riding existing HPC/government channels while CPUs remain the revenue bedrock. Sugon tie-up could accelerate system-level offerings as domestic alternatives mature, especially in heterogeneous computing systems.
🧪 Specialists
A mixture of startups and established players pursuing ASICs and other specialized hardware paradigms. While the Ascend, Hanguang 800, and Cambricon MLU lines are technically ASICs, their incumbency separates them from this bucket.
SOPHGO / SOPHON (算能科技)

2016 | sophgo.com | Private | Entity Listed 🚩
Bitmain-lineage consolidation of SOPHON (cloud/edge TPUs) + CVITEK (edge vision SoCs) into an end-to-end AI stack spanning BM1684X/1688 to the new BM1690 datacenter TPU, plus SG-series RISC-V CPUs and MLOps/toolchains. Recent flagship SC11-FP300 (BM1690, 256 GB LPDDR5X, ~1.1 TB/s) and a 128-TPU liquid-cooled “SuperNode” target LLM inference at scale; the SophNet service fronts popular domestic models.
Historically strongest in video analytics and city/industrial AI; 2025 marks a pivot to mainstream LLMs. CAICT validated SC11-FP300 against DeepSeek-R1-671B inference; broader hyperscaler uptake remains to be proven, but product cadence and platformization are heading in the right direction.
Zhonghao Xinying (中昊芯英)

2018 | zhcltech.com | 605255.SH (Pending SSE inquiry)
Hangzhou TPU upstart founded by a Google TPU alum (worked on v2/v3/v4); markets “GPTPU” training chips (刹那/Chana) with 1,024-chip scaling and a first “Taize” cluster concept. Positioning is assertive on perf/$ versus “overseas GPUs.”
Pilots are tangible: Guangdong Unicom’s initial 32-node TPU center slated to grow, China Mobile Tianjin’s TPU intelligent computing center with Taiji servers, and a Zhejiang University research platform. But corporate maneuvering (reverse-merger path, unusual trading signals) and aggressive revenue claims raise a lot of red flags.
Moffett AI (墨芯)

2018 | moffettai.com | Private
Silicon Valley-founded, now Shenzhen-based. Highly promising sparse-first accelerator company (Antoum chip/S4/S10/S30) focused on algorithm-hardware co-design for high-efficiency inference; adjacent work touches PIM/NDP and compiler/runtime research. Public technical presence includes Hot Chips, MLPerf, and a long paper trail on sparsity/near-data computation.
Large-scale hyperscaler adoption not yet substantiated, but public inferencing benchmarks support SparseOne cards for large model deployments. The bet is that structurally sparse LLMs + memory-centric designs can deliver outsized perf/W once software maturity and workloads align.
InnoStar Semiconductor (昕原半导体)

2019 | innostar-semi.com | Private
Interesting ReRAM/PIM specialist tackling the memory wall by colocating compute with storage (“ATOM” memory-compute). Backed by a mix of global and domestic capital (e.g., KPCB, Lam Research, Ant Group, ByteDance), reflecting both technical ambition and strategic relevance.
This is a platform-stage play where success hinges on reliable ReRAM arrays, compiler/tiling toolchains, and marrying the parts to transformer-era dataflows. As performance data is not available and commercial adoption has yet to be publicized, the inclusion is thematic more than a endorsement of their specific offering.
🐢 Trailing Incumbents
Established or older GPU incumbents whose commercial adoption is trailing newer competitors.
Iluvatar CoreX (天数智芯)

2015 | iluvatar.com | Private
Early GPGPU entrant (founded 2015) with IxRT SDK and the Tiāngāi (training)/Zhìkǎi (inference) lines; leadership turbulence (chair/CEO shuffle, probe) but continued technical progress and financing. Tiāngāi 100 was among the first 7 nm domestic training GPUs; follow-ons target parity with A100-class baselines in select tasks. 天该150 barely outside the A100 performance and efficiency window in energy-compute analysis.
Adoption has skewed to consortiums and research: BAAI training >70B-param models and integration at the National Supercomputing Center in Wuxi show capability; within heterogeneous clouds, presence is modest. Strategy favors ecosystem building and pilots over mega single-tenant wins.
Denglin Technology (登临科技)

2017 | denglinai.com | Private
Niche GPU/accelerator vendor with the Goldwasser II family (from 15–150 W SKUs covering MXM to PCIe). Positioning emphasizes INT8/FP16 density at low power envelopes rather than head-to-head datacenter training.
Commercially, the most visible activity is an “AI+ PC” tie-up with Lenovo; beyond that, evidence of large-scale traction is limited. Reads as an edge/embedded play more than a hyperscale contender.
💩 狗屎
Companies that have thus far failed to demonstrate any commercial viability for AI accelerators whatsoever, but tenure in the industry forces a mention.
Jingjia Micro (景嘉微)

2016 | jingjiamicro.com | 300474.SZ | Entity Listed 🚩
Changsha-based, defense-rooted fabless GPU/SoC designer and one of China’s longest-standing GPU houses; a designated “National Specialist, Unique, and New Key Little Giant.” The Little Giant status delivers both hard benefits (non-dilutive grants, priority “Big Fund” access, policy-bank credit) and soft advantages (procurement preference, reputational signaling). Founders/executives came from CETC 38th Institute with NUDT pedigrees.
Adoption concentrates in avionics/radar and government PC/workstation localization—little evidence of modern AI workloads; H1’25 revenue fell ~45% YoY with GPU segment down ~63%, indicating continued reliance on PLA/SOE demand. Has been completely unable to materialize early leads or government advantages in product development and commercial deployments for AI workloads. JM11 chip line seems to be a last-ditch effort to remain in the race.
Data & Methodology
I’ll summarize the scope of this analysis in the below table, then expand on some areas I know will have the comments section fraught with whataboutisms.
The attributes I care about revolve around energy-compute fundamentals, commercial traction, and leadership acumen. In absence of demonstrable commercial progress, strategic backing or announced collaborations in high-profile “Eastern Data, Western Compute” (东数西算)16 and Intelligent Computing Center projects are helpful, but not a substitute.
Introducing the “Silicon Vanguard” Dataset
I’ve compiled first-party and trusted third-party resources on foreign and domestic chip performance specs into a single artifact I’m calling the Silicon Vanguard dataset (for lack of a better name for now).
This initial version, which I’m sharing publicly, combines performance data from company resources, securities filings, semiconductor conference presentations, reputable equity researchers and industry analysts, and more. Third-hand data reported by tech bloggers or general tech media is more speculative than helpful, so I’ve ignored it at the expense of relative completeness of the dataset.
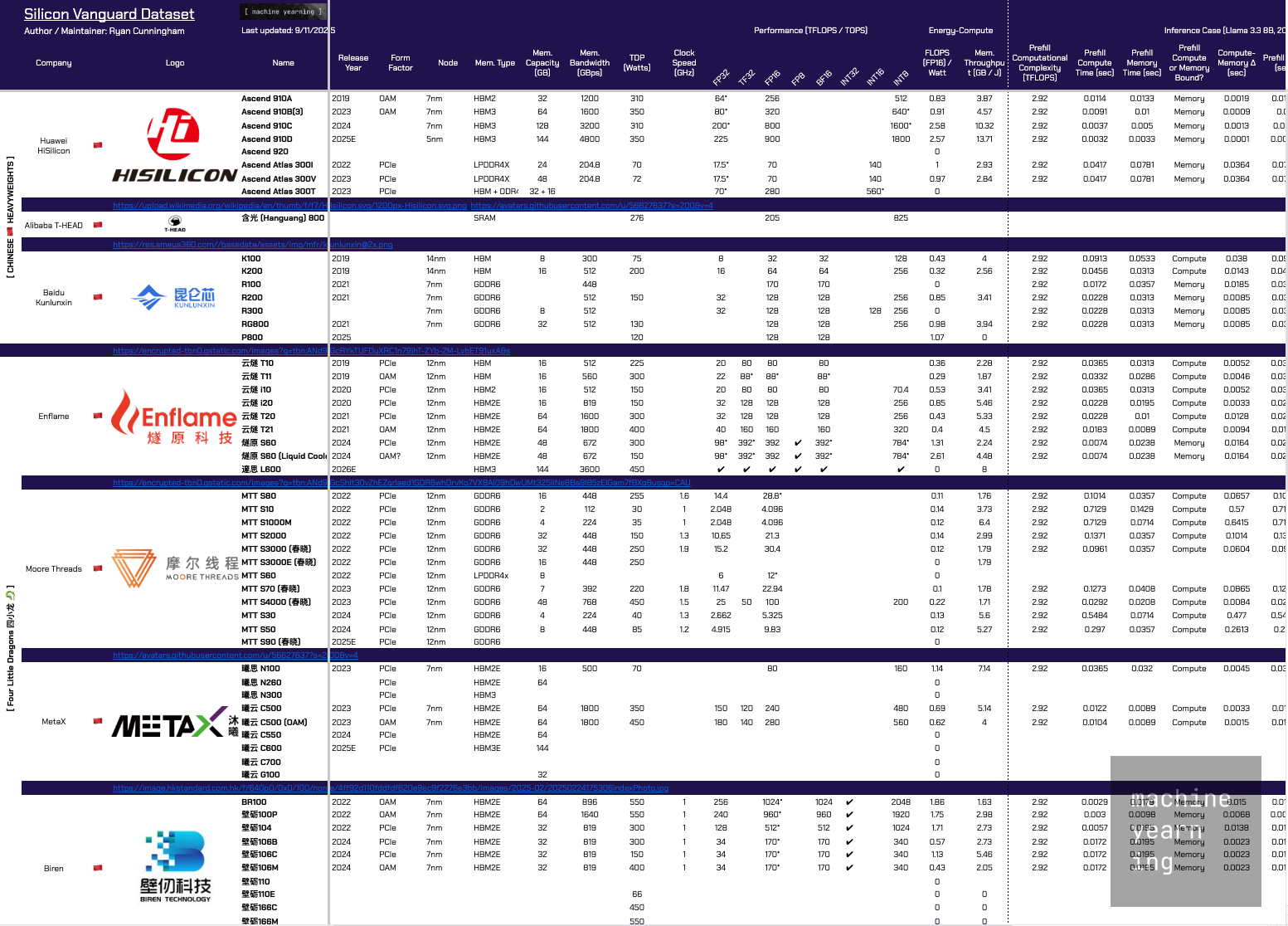
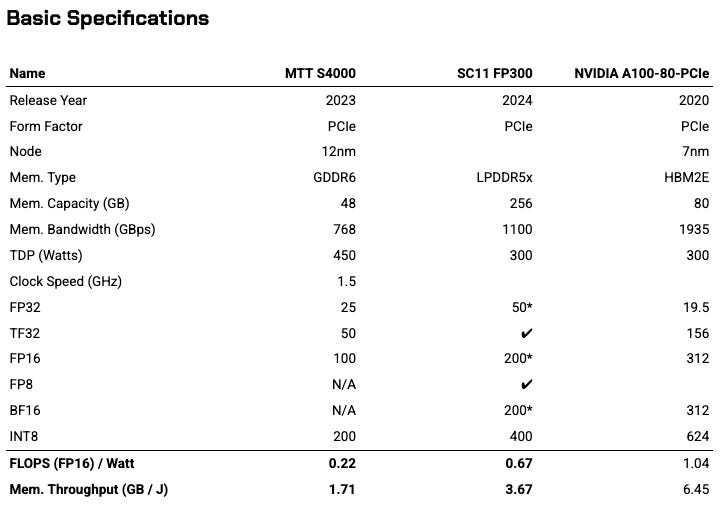
Source: Silicon Vanguard dataset (Machine Yearning).
In addition to basic specs, there are energy-compute metrics and hand-calc’d theoretical inference throughput for various cases. This will be expanded in future versions.
For now, let’s take a quick peek at some of the raw performance figures.
Raw Performance
On a gross basis, the gap in performance between American and Chinese accelerators is pretty stark. At a median computational throughput of 96 TFLOPS, Chinese accelerators trail American ones by a whopping 722 TFLOPS - about the equivalent of a Tesla V100, which precedes current cards by 4 generations. Chinese accelerators in the upper crust of performance beats out an A100, but not an H100 without using sparsification techniques.
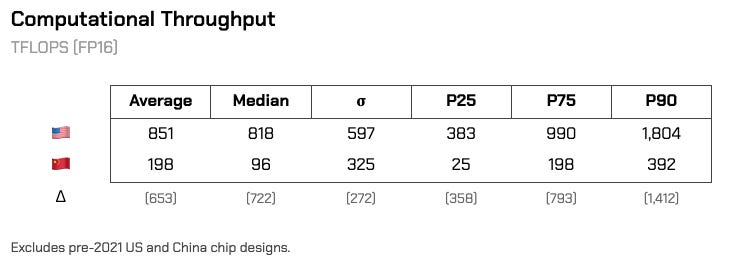
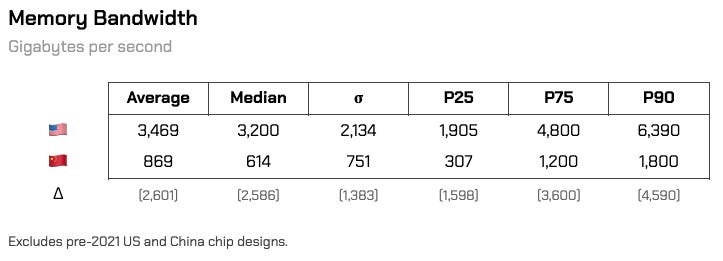
Memory bandwidth speeds tell a similar story. On strictly a hardware basis, HBM restrictions hold back most Chinese chips on memory performance, though upper tier accelerators are landing somewhere around an A100 in performance. Inference acceleration toolkits are attempting to get around this problem while CXMT improves domestic HBM production quality.
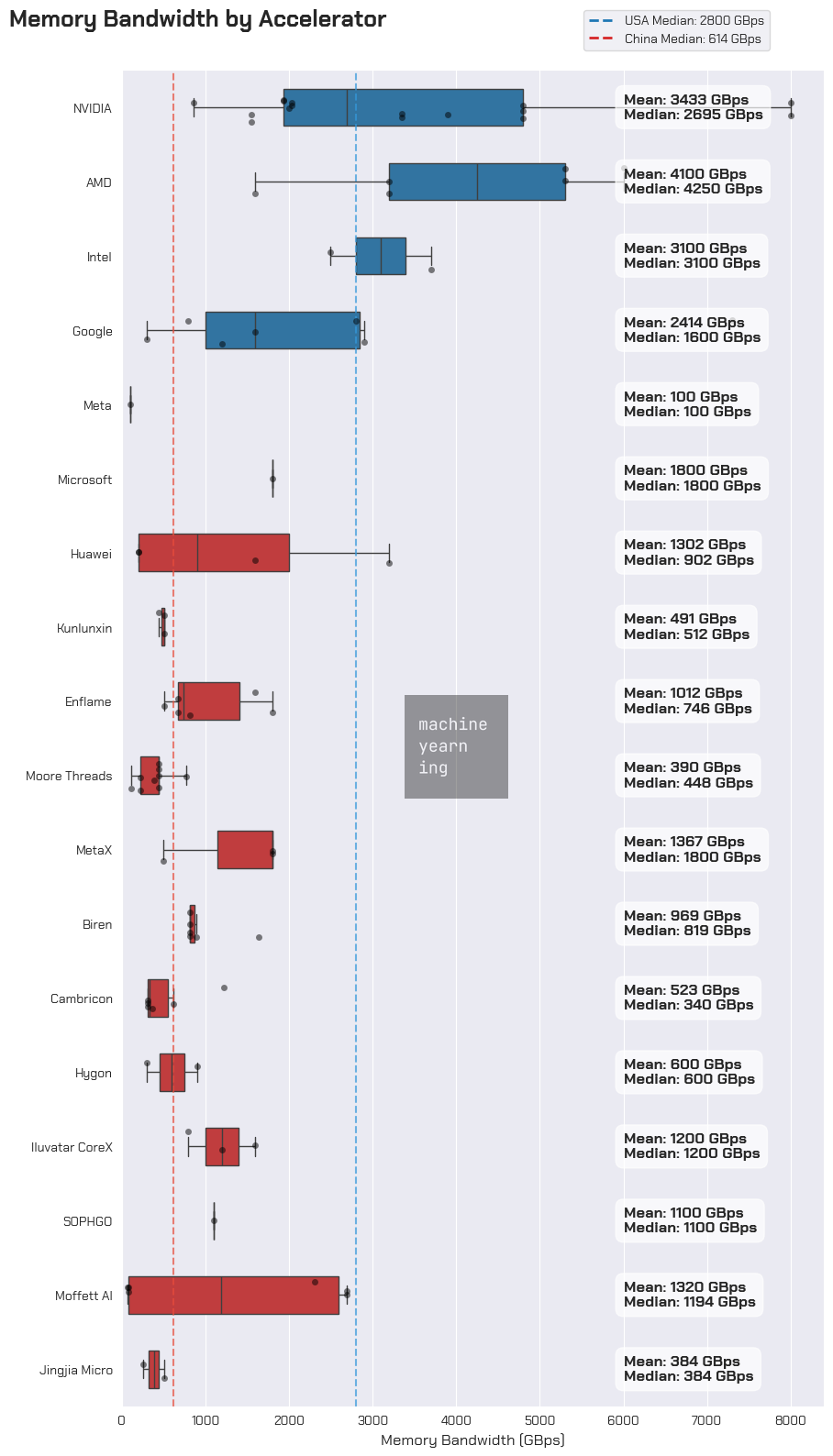
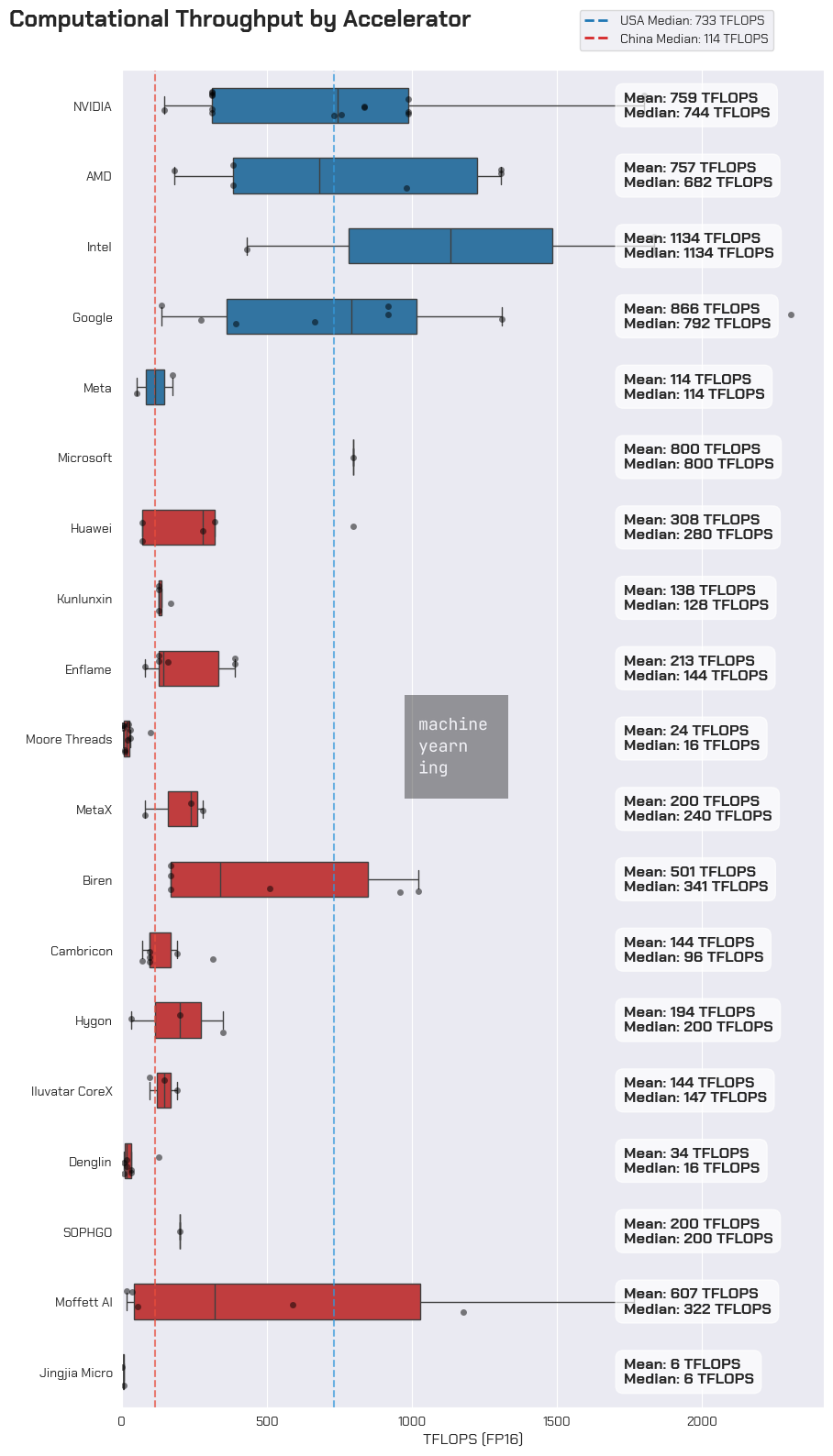
Of the Chinese accelerator cards for which we have data, the best performing families seem to come from Huawei, Enflame, and MetaX. We haven’t yet found performance data on Cambricon’s latest accelerator, the 思元590, but industry adoption trends suggest this would be a top performer as well. Biren is excluded from this list as recorded performance data is from their TSMC-produced cards, which are no longer accessible since being added to the entity list.
Energy-Compute Performance
We start by looking at two primary energy-compute metrics - computational energy efficiency and memory energy efficiency. These are measured in FLOPS / Watt and bytes per joule, respectively. Both of these metrics give an indication for what kind of performance we can expect in a limited energy envelope.
The objective for energy-compute practitioners is to maximize tokens per joule (subject to quality and throughput thresholds). AI accelerator cards don’t need to have the absolute best stats - beyond a certain threshold of size, speed, and power, they just need to be good enough to handle industry standard models. Hence the Chinese ecosystem’s convergence on DeepSeek / UE8M0 FP8 precision as a newly established model performance standard.17
So, with these data, we can hand-calc tokens-per-joule by calculating the number of operations required to run a specific model (in this case, Llama 3.3 8B) at a specific precision (FP16, so 2 bytes per parameter). After determining whether the operation is compute-bound or memory-bound, we can solve for the time it takes to generate a single token during the decode sequence (seconds / token), and flip it to get the peak theoretical throughput (tokens / second). Based on the hardware’s energy consumption, we finally solve for tokens / joule.18
Alas, when translated into production workloads, both advantages compound for American chips. In a theoretical 8B parameter model inference run, American accelerators can hit around 200 tokens / second. Most Chinese accelerators can only hit about a quarter of that.
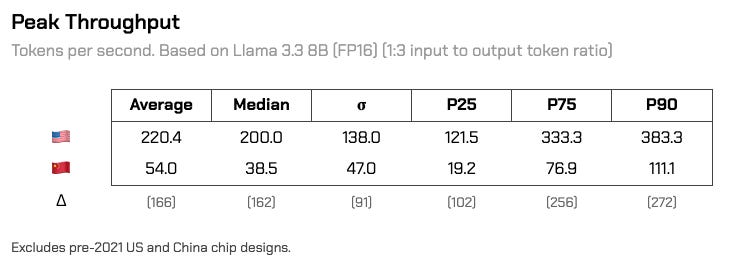
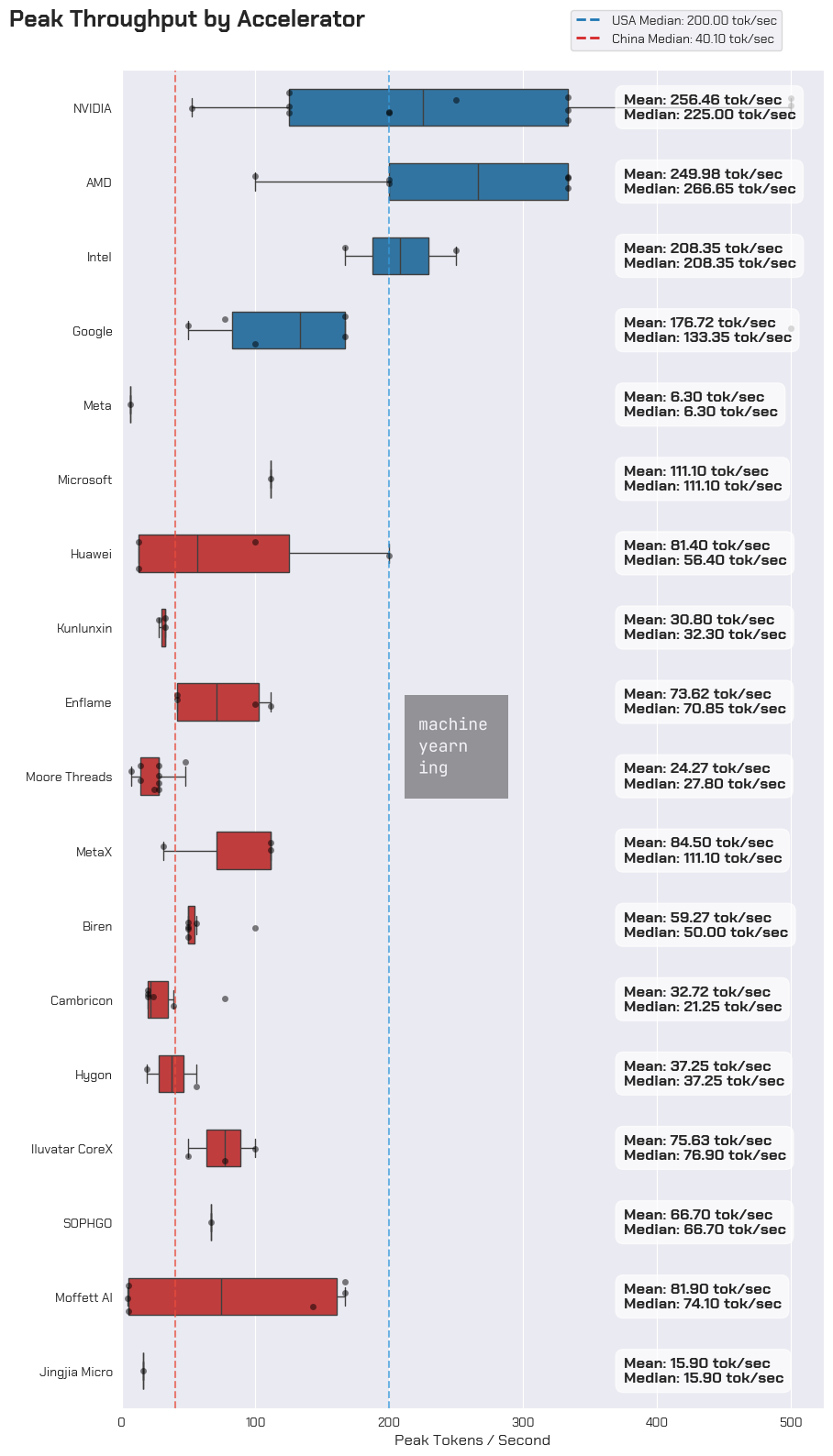
The gap in energy efficiency between American and Chinese chips is narrower than the raw performance gap, but still there. Across the board, American chips yield about 58% more tokens per joule than Chinese chips do. Peak throughput significantly affects this figure - time is energy, after all.
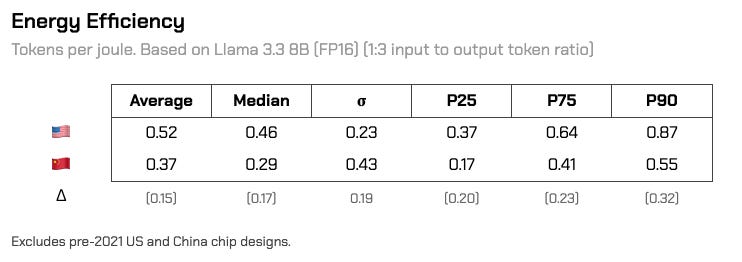
Interestingly enough, of the American chip line the NVIDIA H20 is the most energy-efficient at 1.1 tokens / joule, even beating out the Blackwell lineup at 0.95. The Ascend 910C is China’s most energy efficient chip at 0.86 tokens / joule, with the exception of Moffett AI’s SparseOne S30 (which natively supports up to 32x sparsity), and yields a whopping maximum of 2.72 tokens / joule. Aside from Moffett, nearly all GPUs and TPUs in this dataset are stuck underneath an efficiency frontier of ~1 token / joule.
If the Ascend 910D performs as rumored - up to 900 TFLOPS (assuming at FP16)19, 4,800 GBps of memory bandwidth in a 350W package - this would push its peak throughput to ~333 tokens/sec at an energy efficiency rating of 1.27 tokens / joule.20 That would place it in the 75th percentile of American chip inference performance while also making it the most energy efficient chip on the market, without sparsity.
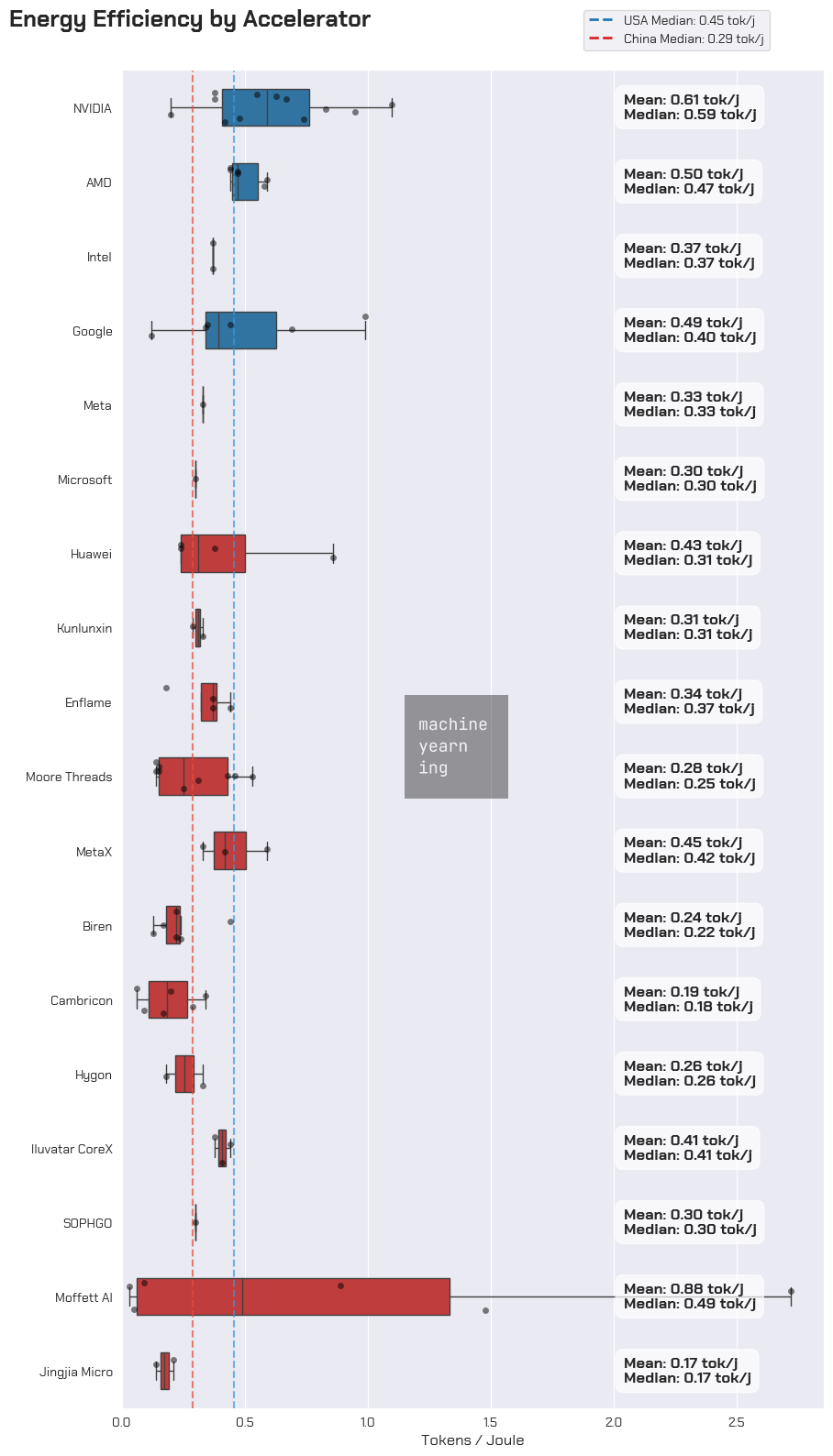
FLOPS Are (Not) All You Need
Ending the analysis here would be pretty unsatisfactory. Rumors on the Ascend 910D are fine, but we’re concerned with discerning the ability for China to domestically serve its inference needs today. We can’t let perfect - or in this case, leading edge - be the enemy of “good enough.”
Why don’t I care as much about raw FLOPS? Well for one, it wouldn’t be as fun an analysis if I did, and two, that’s a misleading indicator for the overall utility of an accelerator card. Hardware is just one piece of the puzzle.
Past a certain point, we do not care if an accelerator card is best-in-class. We care only if it gets the job done.
I already know this statement is going to ruffle some feathers. It would sound like cope coming from a Chinese commentator. It’s well-understood that most developers would prefer to use the best chips and software available to them. But since the US seems keen on alienating NVIDIA from Chinese buyers as much as possible (Secretary Lutnick’s insistence on “addicting” Chinese engineers to America’s technology stack is just ridiculously Opium War-coded… it’s hard to believe that isn’t somewhat intentional21), we might as well try to figure out what constitutes a passable domestic replacement.
With this in mind, how do we determine what is considered “good enough” for the Chinese AI ecosystem?
Industry Certifications
Without applying some guardrails to it, that could be an entirely vibes-based debate. We could set an arbitrary threshold like NVIDIA A100-grade, but this still feels loose.
One of the takeaways Paul and I had from WAIC was the universal convergence on DeepSeek R1 671B as the effective “Wintel” standard for the AI era. This time around, instead of “Intel Inside” stickers, WAIC booths for vendors like SOPHGO, Enflame, and Moore Threads all featured all-in-one systems (supernodes) which they loudly proclaimed capable of running “full-blooded” DeepSeek R1, that is, the single-precision 671B parameter model. Seriously, the branding was everywhere.
When these chips costs tens of thousands of RMB per card, should unwitting procurement teams simply take these vendors at their word? This is a major question that even American neoclouds are grappling with - not just whether the chips work, but whether I can make a profit by hosting them.
Luckily, a third-party certification ecosystem is emerging to provide clarity. The China Academy of Information and Communications Technology (CAICT), a subordinate of the Ministry of Industry and Information Technology (MIIT), is in the business of conducting third-party benchmarking, assessments, and certifications for all kinds of hardware and software applications.22 Recently, it seems they’ve begun issuing certificates for “AI Chip and Large Model Adaptation Tests,” verifying that applicant vendors’ hardware can passably run inference for DeepSeek R1 671B.
This is useful for a few reasons:
It confirms beyond a reasonable doubt that DeepSeek R1 isn’t just a marketing push, it’s actually being adopted into industry baseline benchmarking
It contributes to our understanding of how the private and public sector in China can provide operational clarity to both vendors and purchasers
It gives us a concrete “good enough” threshold to conduct our own assessment
SOPHGO SC11-FP300 (Issued 2025-06-26)
The SC11 FP300 is SOPHGO’s latest TPU chip - the BM1690 - in a PCIe form factor. It uses LPDDR5x memory, and is much more optimized for energy efficiency than a GPGPU. This emphasis on energy efficiency is part of SOPHGO’s heritage as Bitmain’s original ASIC business for cryptocurrency mining.

Unlike the MTT S4000, the SC11 FP300 is confirmed to work with FP8 precision workloads - very important for future training and inference needs.

Advanced Computing Products
AI Chip and Large Model Adaptation
Test Certificate
Xiamen Suanneng Technology Co., Ltd.
Room 702-01, Xinghui Building, No. 9 Zengcuo'an North Road, Software Park, Xiamen Torch High-tech Zone
Product Name: Suanneng SC11 FP300 Computing Card
Product Model: SOPHON SC11 FP300
After testing by the China Academy of Information and Communications Technology, your SOPHON SC11 FP300 computing card has passed.
"AI Chip and Large Model Adaptability Passability Assessment Software and Hardware Environment and Test Details" (FT-L06-0196-01)
This certificate specifies the passability adaptation requirements for inference scenarios. The adapted large model is the DeepSeek-R1 671B large model developed by Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd.
This certificate is hereby issued.
Moore Threads MTT S4000 (Issued 2025-04-30)
The MTT S4000 is the latest data center card in the Moore Threads lineup. It’s a general-purpose GPU (GPGPU) that uses the ChunXiao chip architecture, Moore Threads’ 2nd gen chip.

It comes with 48GB of GDDR6 memory, the same kind you’ll usually find in NVIDIA consumer GPUs. In addition to the KUAE, Moore Threads had an OAM module and edge device on display at their booth.

Source: Sina Weibo.
Advanced Computing Products
AI Chip and Large Model Adaptation
Test Certificate
MooreThread Intelligent Technology (Beijing) Co., Ltd., Building 3, Wangjing International R&D Park, Chaoyang District, Beijing. Product Name: MTT S4000 Training-Initialization Computing Card
Product Model: MooreThread MTT S4000
After testing by the China Academy of Information and Communications Technology, your company's training-initialization computing card, the MooreThread MTT S4000, has passed the inference scenario passability requirements of the "AI Chip and Large Model Adaptability Passability Assessment Software and Hardware Environment and Test Details" (FT-L06-0196-01). The adapted large model is the DeepSeek-R1 671B developed by Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd.
This certificate is hereby issued.
As the rest of the Four Little Dragons seek a public offering, I expect we’ll see similar CAICT certifications as a positive signal for commercial adoption in the IPO process.
Calculating “Good Enough” Performance
The MTT S4000 and SC11-FP300 aren’t the best chips in our domestic chipmaker inventory, but they do provide useful examples to determine our “good enough” threshold. We can update this prior as new CAICT certifications become public.
Strictly on an energy-compute basis, both chips still fall short of NVIDIA’s A100 series from 5 years ago. But they offer decent enough performance to warrant a closer look.
First, we need to assess what takes longer: processing the entire prompt, or moving the weights from memory to the logic chip for processing. This determines whether the prefill stage is compute-bound or memory bound, respectively. We take the greater of those two values (in seconds), and add that to the total time it takes to decode our output sequence. The decode stage is almost always memory-bound.
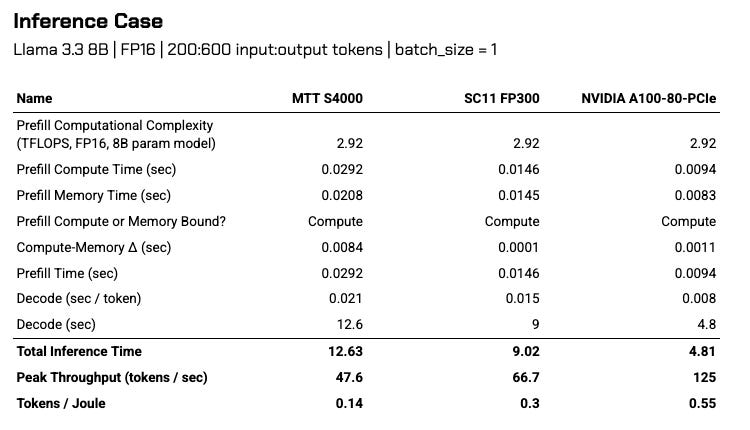
From this limited dataset, it seems that CAICT deems peak throughput of ~47.6 tokens / sec passable for an 8B parameter model on a single card. Keep in mind that all tested hardware come in multi-card server node configurations - it’s likely the CAICT tests were conducted on those systems rather than single-card inference.
Nearly 13 seconds of inference time for an 8B model is a little long for my taste, and even a 3-generation old card like the A100 can do that in half the time at much better energy efficiency. Regardless, this is as good a starting point as any.
We’ll therefore set our passability threshold, as suggested by CAICT, for FP16 inference on an 8B model at:
With those requirements in place, we can now conduct a more informed analysis than just raw performance specs would have afforded.
Technical Analysis
As a refresher, the triple-product advantage is the compounding effect that moderate gains in individual vectors (energy efficiency, throughput speed, model quality) create when multiplied together.
This means that even if hardware is only “good enough” on efficiency and throughput speed, collaborative innovations in distributed inference, sparse memory operations, mixed precision, and so on can reduce computational complexity to fit within those limitations. Not to mention having plenty of surplus power to support initial energy footprints.
While NVIDIA and AMD are undoubtedly pushing out high-quality hardware, these systems have been stuck on the same iso-efficiency frontier: ~0.52 (± 0.21) tokens / joule since 2016. Newer systems boast incredibly powerful computational performance and boosted memory speeds, but without leveling off power draw for new chips, their energy efficiency hasn’t improved that much.
If an ecosystem is successfully co-designing models, hardware, and inference environments, then native participants of that ecosystem stand to benefit the most. Put another way, innovation is happening on all fronts.
1. Product Performance
Standouts: Huawei, Enflame, MetaX, Moffett AI.
CAICT certification provides a useful benchmark for industry adoption and acceptability. Huawei, Enflame, Moore Threads, MetaX, Hygon, Iluvatar CoreX, SOPHGO, and Moffett AI each have at least one “passable” card based on inferred CAICT guidance (tokens / joule >= 0.14, peak throughput >= 47.6 on Llama 3.3 8B).
Only Huawei, Enflame, MetaX, and Moffett AI have cards within spitting distance of A100 inference performance.
We’ll start by plotting the SKUs of all vendors with available data on a throughput vs. power scatterplot. This highlights both accelerator performance and energy efficiency characteristics.
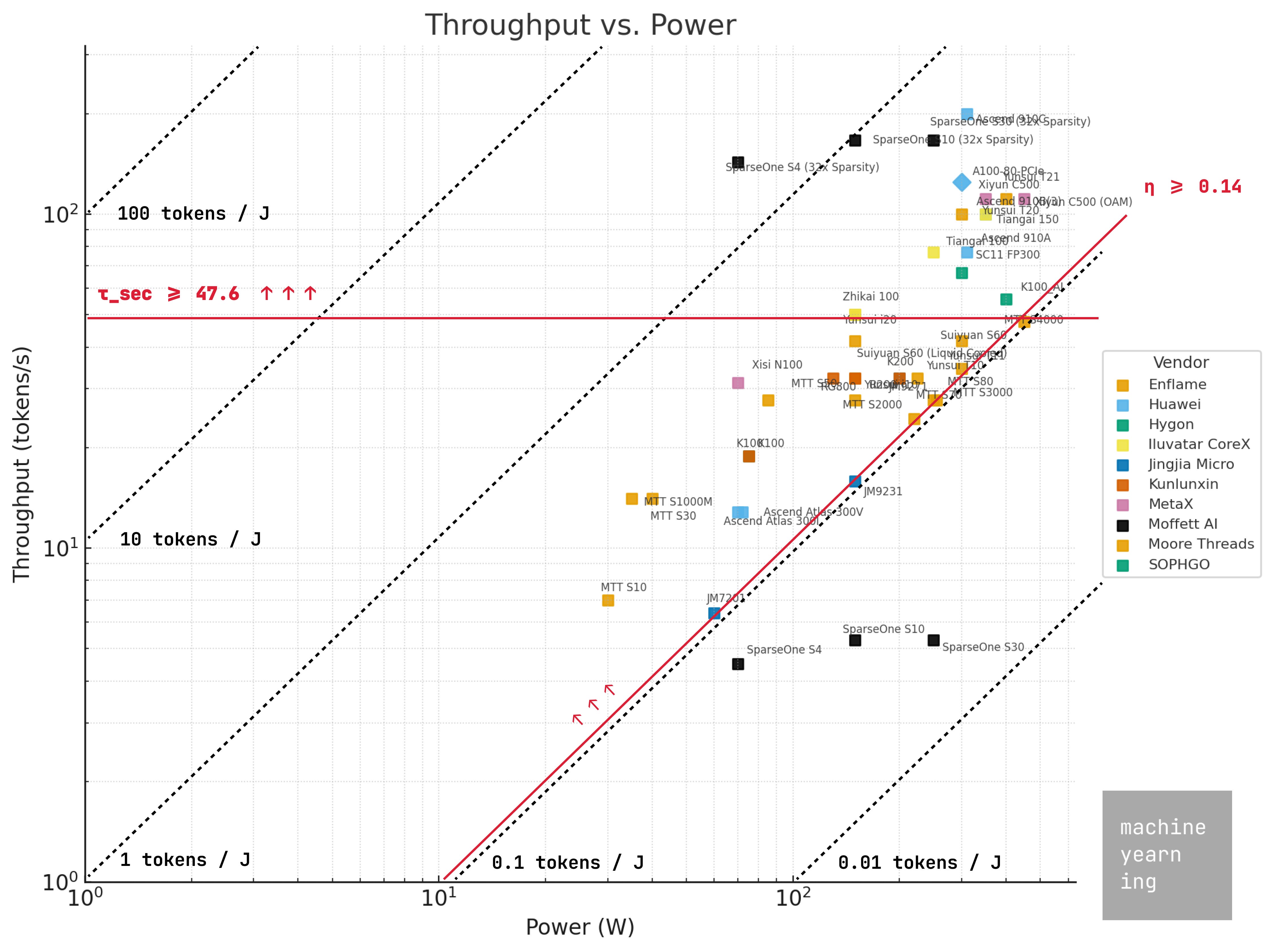
As a reminder, our “good enough” energy-compute thresholds for Llama 3.3 8B inference in FP16 precision are:
Throughput: τ_sec >= 47.6 tokens / sec
Energy Efficiency: η >= 0.14 tokens / joule
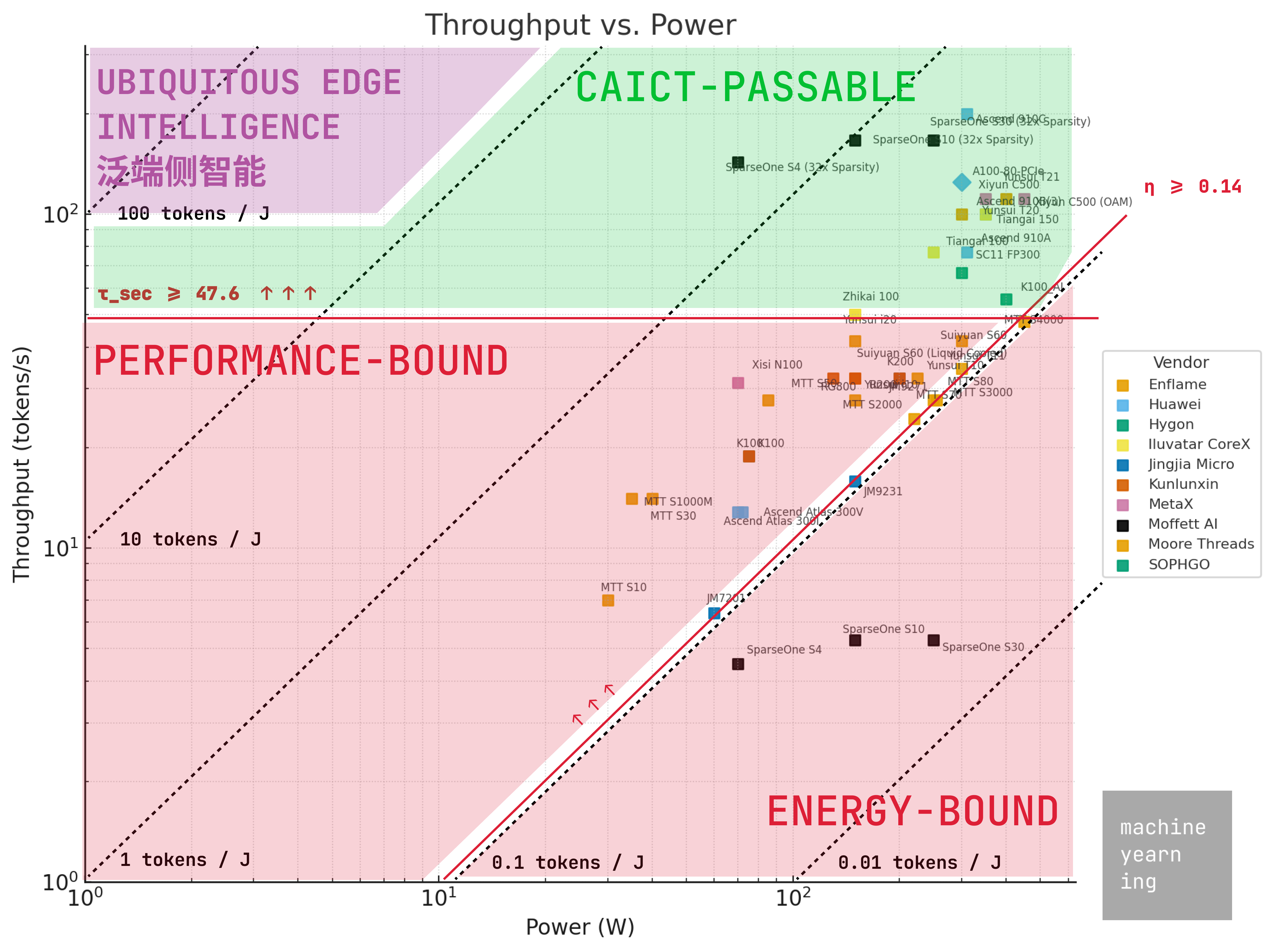
Readers may also remember the “Ubiquitous Edge Intelligence” milestone (the purple zone) discussed at WAIC 2025. This is the north star for domestic model-chip co-designs, defined as the following:
Throughput: τ_sec >= 100 tokens / sec
Energy Footprint: E < 20 watts
Energy Efficiency: η >= 20 tokens / joule

Applying those restraints leaves 10 of 16 vendors having at least one SKU which makes the cut. Insufficient information on Denglin Technology, Zhonghao Xinying, Innostar Semiconductor, and T-HEAD prevents placing them on this graph, though Innostar and T-HEAD’s approaches to on-chip memory would likely place them in an energy-efficient tier.
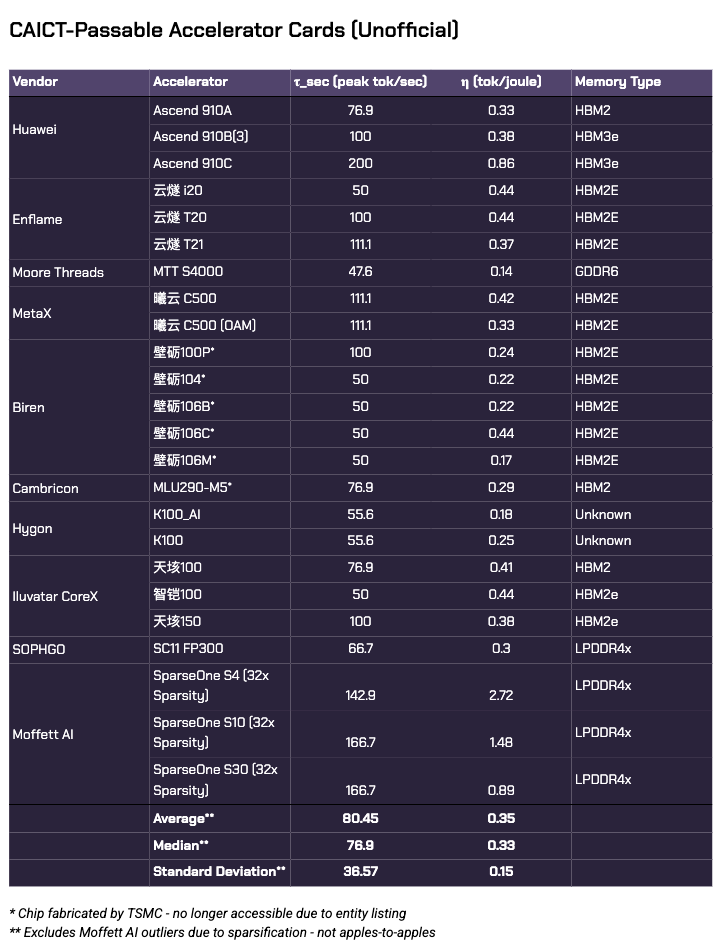
However, Biren and Cambricon’s passable products are from an older generation of chips, back before they were added to the U.S. Entity List in 2022. Both have since shifted wafer production to SMIC, and performance data has been harder to come by for their newer lineups. So for fairness, we should remove these from the list. This doesn’t mean that newer chips powering Biren’s 壁砾166 lineup or Cambricon’s 思元590 series aren’t passable - we just don’t have the data for that yet.
That leaves 8 / 12 companies - Huawei, Enflame, Moore Threads, MetaX, Hygon, Iluvatar CoreX, SOPHGO, and Moffett AI - still in play.
Speaking to the considerable performance gaps, most vendors fall out of favor if we raise the passability threshold to within striking distance of an A100. Of the 39 original accelerator cards we have data for, only 4 remain: the Huawei Ascend 910C, Enflame 云燧T20, MetaX 曦云C500, and the Moffett AI SparseOne series.
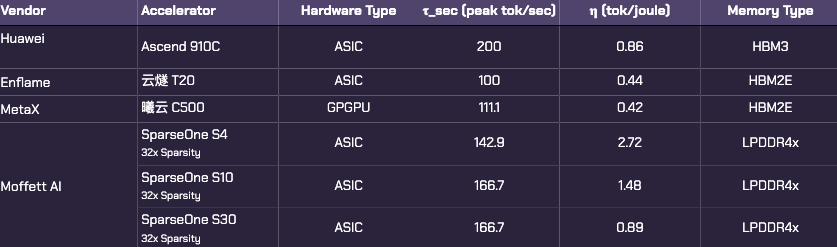
I’m including Moffett AI in the mix as hardware-specific innovations have enabled high sparsification factors of up to 32x which, on <250W form factors, yield incredibly energy efficient computation. While the 32x case is visible, even 16x and 8x are sufficient to meet the CAICT bar.
Notably, MetaX is the only general-purpose GPU (GPGPU) in this list. The others are ASICs!

Memory Comparison
Note that with the exception of Moore Threads, SOPHGO, and Moffett AI, nearly all accelerators seem to require at least HBM2E-tier memory to make this list.
Most domestic chip designers use HBM2E or earlier, with some using GDDR6 or LPDDR5x memory. Cambricon, Enflame, Biren, MetaX, and Iluvatar CoreX all use HBM2E in their latest chips, with Enflame’s upcoming 邃思L600 rumored to be an early candidate for HBM3.23 After its initial entity listing and until its 思元590 chip (2022-2024), Cambricon used LPDDR5 memory, as does Moffett AI (LPDDR4x) for its low-powered SparseOne cards. Finally, Kunlunxin and Moore Threads all use GDDR6 memory.
The thermals, tradeoffs, and physical limitations of memory tech will be the subject of a future post. For now, it’s safe to assume that domestic chip designers will eventually have to align with a sovereign domestic supply chain for memory chips, which at the moment, remains a bottleneck to more advanced chip production.24
Sparse Computing
Critical to Moffett AI’s outperformance is its approach to sparsity. In neuroscience, it’s widely understood that human wetware leverages a high degree of sparsity in computations - in fact, less than 2% of neurons actually fire for any given input. This is a major contributor to the human brain’s considerable computational energy efficiency.
“Sparsity” in AI workloads refers to the proportion of zeroes (or near-zero) values in a neural network’s parameters or activations - the more zeroes, the fewer operations and data to have to work with. At most, typical GPUs like NVIDIA’s lineup can only natively support 50% (2x) sparsity.
Sparsity is represented in either percentages or multiples (e.g. 50% of weights set to zero = 2x sparsity, 87.5% = 8x, 96.9% = 32x). Some research has shown that LLMs can be sparsified to high degrees (often 50-90% sparsity) with minimal loss in accuracy when done properly.
A few years ago, Ian Chen and Zhibin Xiao, co-founders of Moffett, published a paper outlining their approach to this problem. The Antoum chip forms the core of their hardware lineup, the SparseOne cards, which are capable of up to 32x sparsification. While there is an inherent accuracy-speed tradeoff with sparsification (you are losing some information after all), the team found considerable speedups in throughput (and therefore, energy efficiency) with minimal accuracy loss.
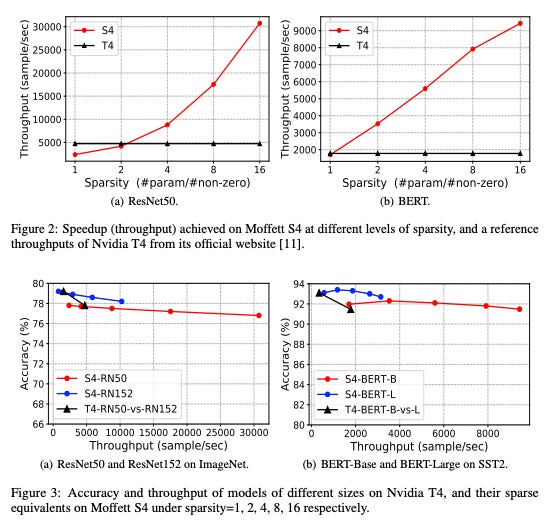
The aforementioned S4 in their paper only draws 70W of power. The SparseOne S30, a 250W variant, previously demonstrated production-grade performance on large 100B+ parameter models like BLOOM-176B - 432 tokens / second in an 8-card deployment.25
Moffett AI has also repeatedly participated in MLCommons’ MLPerf Inference benchmarks, receiving consistently high marks for its SparseOne lineup. The S30 in particular nearly doubled H100 throughput on common LLM workloads on a 2.8x smaller energy footprint, yielding a ~5x boost in energy efficiency with virtually no loss in output quality.26

Finally, that Moffett’s Antoum cards were deployed on nodes from reputable OEMs (H3C and Inspur) demonstrated minimal or limited customizations required to run these hardware, hinting at commercial viability. Inspur is also an investor in the company.27
Future Moffett cards are confirmed to support FP8 precision workloads.28
2. Developer Adoption
Standouts: Cambricon, Moore Threads, Huawei, Enflame, MetaX.
Laggards: Iluvatar CoreX, Biren.
NVIDIA’s CUDA ecosystem retains top-billing in developer preferences, and CUDA-like compatibility is a positive adoption factor for GPGPU designers like Enflame, Moore Threads, and MetaX.
Significant investment in transcompilation tech a positive tailwind for custom silicon designers like Cambricon. Non-heavyweights pushing their own custom languages, like Iluvatar and Biren, are struggling.
Heterogeneous frameworks, transcompilation, and open-source strategies will contribute to CUDA moat erosion over time.
Before you ask, I’m not going to give a definitive answer on if and when NVIDIA’s CUDA moat gives way to domestic innovation. But I’ll highlight some contributing factors we can track.
Hardware isn’t useful if developers hate having to work with it. During our China trip, we spoke to a host of Chinese cloud providers asking about developer adoption of these various SDKs. Universally, preferences for CUDA (and even ROCm) remain over domestic alternatives thanks to their much larger extant developer and troubleshooting communities - a valuable moat to have.
Domestic players recognize this and attempting one of three paths:
Seek CUDA compatibility. Suiyuan plans to invest 20% of its IPO fundraising to develop a CUDA-compatible tool chain, with a goal of achieving 90% operator compatibility by 2025, and the migration cost will be reduced to 40 man hours per person. MetaX has also announced that its C500 series (and all future cards) would be CUDA compatible. Kunlunxin’s lineup is also reportedly CUDA compatible.
Press advantages into software. Huawei recently announced it would be open-sourcing CANN to help build up its developer ecosystem. Older players like Iluvatar CoreX and Biren are pushing their own custom programming languages, but may be facing adoption headwinds as a result.
Build out transcompilation libraries. Both Cambricon and Moore Threads have invested considerable resources into their in-house transcompilation libraries, QiMeng-Xpiler and MUSIFY, which convert CUDA into their native programming languages (BANG C and MUSA).
Programming Stacks & CUDA Compatibility Roadmaps
Of course, Heavyweights don’t have to worry about developer adoption, since they have the cloud real estate to justify significant hardware R&D investments. Third-party players, like the little dragons, have to partner with hyperscalers in some capacity if they want to see widespread adoption, and can grease the wheel with CUDA compatibility. But Huawei wants to establish itself as the de facto leader of the sovereign semiconductor ecosystem, and to do that, they need developers - lots of developers - to use CANN.
During this transitional stage, an “abstraction layer” market seems to exist for building transcompilation libraries, converting code written in CUDA into hardware-specific accelerator code. NVIDIA obviously wants to restrict this as much as possible, and has banned such translation layers in its licensing terms since 2021.30
Nonetheless, CUDA optimization and translation remains a big market nonetheless. Readers may remember Sakana AI (Japan’s sovereign research lab) announced, retracted, and re-launched its own CUDA engineer,31 and Y Combinator featured a similar request in its Spring 2025 “Request for Startups.”32 In China, Xcore Sigma (中科加禾) is one such example.33
The challenge with this approach is that third-party optimization libraries will always be a few steps behind first-party equivalents. Without a tight relationship between the software and hardware designers, it takes time for optimizations against those changes to diffuse.
Naturally, this routes highly competitive developers and downstream markets towards natively supported solutions that have the most up-to-date acceleration. This is why for domestic chip designers, reliable transcompilation between common libraries and custom hardware is a must-have. That’s basic network effects.
Moore Threads - MUSIFY
As an example, Moore Threads is promoting its MUSIFY toolkit to convert CUDA code into MUSA (Moore Threads Unified System Architecture), its native programming language. If it works, this would significantly reduce the technical barriers and time costs of switching platforms. Users speculate that it works similarly to ZLUDA, which translates PTX code at runtime.34
Cambricon - Transcompilation
A joint team between Cambricon (including the two co-founders) and ICT-CAS co-developed a transpiler called QiMeng-Xpiler, which converts between more commonly supported libraries (NVIDIA CUDA, AMD HIP, and Intel VNNI) and BANG C, Cambricon’s proprietary C-like language. It can handle these transcompilations with an average accuracy of 95% (admittedly weighed down by Intel), which outperforms both traditional rules-based methods and AI-native approaches.
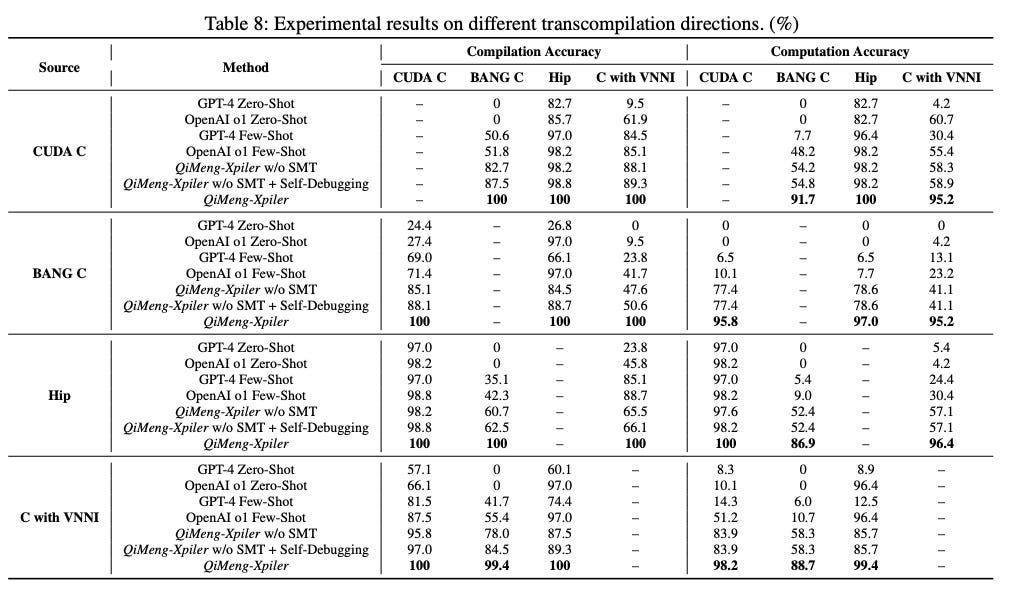
Source: USENIX, Cambricon.
The last thing that developers want to do is debug, hence the preference for well-supported languages like CUDA. Plus, transcompilation can take hours - 3.7 on average - which is a long time to wait before realizing your code is riddled with errors. Even a few percentage points difference in final compilation accuracy can mean hours, if not days, of manual debugging.
Fortunately for Cambricon, while QiMeng failed to generate a functional-program the first time for its most challenging operation in this study (Deformable Attention, ~200 lines of code) around, it didn’t require long for programmers to debug it: half an hour for “senior coders” (software engineers), and 3 hours for “junior coders” (masters students). Plus the original transcompilation time of 4.5 hours, that’s about a day’s work compared to a week’s work of manual transcompilation - a ~20-30x productivity improvement when deployed alongside professional software engineers.
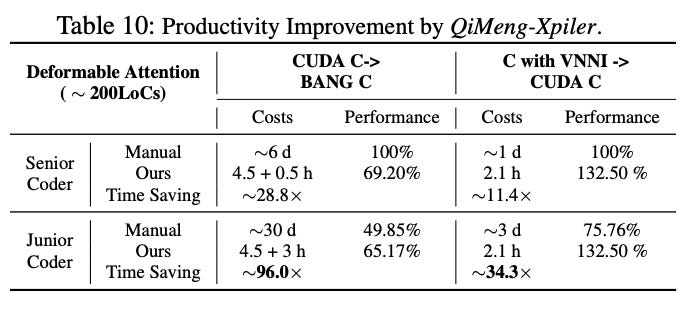
Strategic Analysis
Beyond individual product performance, there are qualitative factors to examine: strategic and financial backers, leadership teams, and commercial track records all contribute to relative standing. But the backdrop for much of this is the fallout and catalytic effects that American export controls have had on the ecosystem. To paint the picture, we’ll start with the entity list impact.
1. Entity List Impact
While being named to the U.S. Entity List has hit some first movers like Biren hard, for others they have been more speed bumps than Great Walls.
Second mover advantages for the other three dragons - Enflame, Moore Threads, and MetaX - seem to exist, as they’ve had an easier time finding commercial adoption from large hyperscalers.
Specifically, HBM is a critical bottleneck holding back domestic chip performance… for now. Time will tell how quickly CXMT / YMTC can ramp up HBM3+ production. Heterogeneous computing and software-first innovations are beginning to evade these bottlenecks somewhat successfully.
For now, poorer SMIC yields (~40%) are contributing to higher unit costs for domestic chips than NVIDIA-produced chips (TSMC at 80-90% yield depending on process node). However, as this improves, unit costs for domestic chips will systemically improve.
Leadership Turmoil: Biren
Founded in 2019, while Biren wasn’t the first domestic GPU company, it was widely considered to be an early darling.
The founder & CEO, Zhang Wen (张文), is the former president of SenseTime and holds a JD from Harvard University + an MBA from Columbia University.35 Notably, he does not come from a technical background, but he is an excellent dealmaker and headhunter: his extensive experience enabled him to assemble an Avengers-class team of founders and executives from Huawei, Alibaba, Qualcomm, and more.36 On the team alone, Biren was able to secure significant amounts of capital - nearly $700M USD and establish early partnerships with other hyperscalers.37
In 2021, Zhang added another heavyweight to the roster - Li Xinrong (李新荣), former AMD executive and its head of China R&D. Curiously, he was added as “Co-CEO,” likely to reinforce the technical leadership acumen Zhang Wen lacked in the executive role.38
Biren debuted its flagship chip, the BR100, in 2022 at Hot Chips 34 and positioned it as a domestic alternative to NVIDIA’s A100/H100 class, emphasizing strong BF16/INT8 throughput, flexible precision handling, and speedy interconnect bandwidth. This was objectively an impressive chip at the time, eclipsing the A100 (released just a year earlier) in several performance metrics.39
However, that conference may have attracted unwanted attention from Biden-era policymakers. Months later, Biren would be added to the U.S. Entity List, starving it from access to TSMC process nodes (and later, HBM from SK Hynix / Samsung) for fabrication.40 Zhang would also go on to lose both his co-founders - Xu Lingjie (徐凌杰) and Jiao Guofang (焦国方) - in the ensuing fallout. Biren has yet to recover its pole position in the domestic market.
There’s a Chinese idiom 树大招风 (shù dà zhāo fēng, “a tall tree attracts the wind”) which captures this problem. This is also probably why most Chinese chip designers are incredibly tight-lipped about performance specs for their product lineups.
Memory Bottlenecking: Moore Threads
Being named to the U.S. Entity List hasn’t helped Moore Threads’ HBM prospects, either - entity-listed or sanctioned companies are typically barred from using HBM products from SK Hynix, Samsung, and Micron, the international memory triumvirate.41 This means their primary options for domestic memory IDMs are Yangtze Memory Technologies Corp (YMTC) and ChangXin Memory Technologies (CXMT).
The majority of leading edge chips from NVIDIA and AMD use HBM3E memory, which is more advanced than the memory types that sanctioned domestic chipmakers have access to. More specifically, HBM3E achieves total package memory bandwidth speeds of over 1.2 terabytes per second (TBps) per memory stack, roughly 3x faster than HBM2E. Advanced cards use multiple stacks of HBM - 4, 6, or even up to 12.
Moore Threads uses GDDR6, rated at or around 512 GB/s. GDDR is the kind of memory you’d find in prosumer gaming GPUs - still good quality, but pales in comparison to HBM.
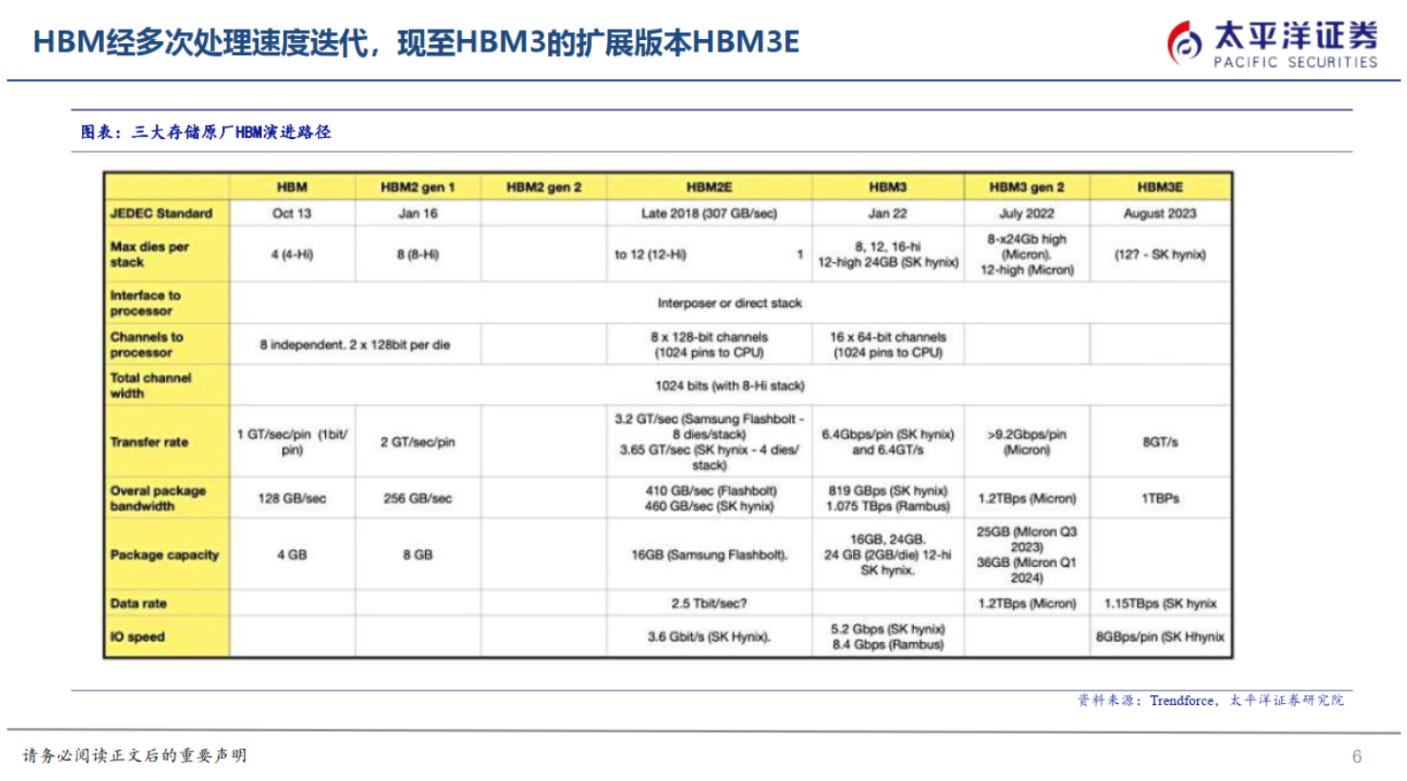
Source: Pacific Securities, CSDN.
Reportedly, CXMT has already been producing HBM2 since mid-2024, and has begun testing HBM3 with select industry partners.42 They expect to enter mass production for HBM3 and HBM3E grade memory chips in 2026-2027. Interestingly, YMTC - which has been producing stacked NAND chips for years - seems to be reaching across the aisle to assist CXMT with hybrid bonding techniques for more reliable stacking and thermal dissipation.43
It could also be the case that since Moore Threads manufactures both consumer gaming GPUs and datacenter cards alike, the decision to use GDDR6 rather than HBM2 may be to simplify its supply chain. Undoubtedly GDDR has pretty steep tradeoffs in comparison. Whatever the case may be, entity listing has definitely impacted the competitiveness of Moore Threads cards against non-sanctioned domestic and foreign competitors.
For more on HBM, I strongly recommend Ray Wang’s guest piece on Nomad Semi.

Lower Yields, Higher Unit Costs
One area where the Entity List is having a measurable systemic impact is domestic chip unit costs. Sometimes, Chinese companies will list more granular cost of goods sold for specific line items in their reporting materials. For our analysis, we have a useful comparison: two Little Dragons, one entity-listed (Moore Threads) and one not (MetaX).
To proxy our deployment costs, $ / TFLOPS is a helpful metric for training, but less informative for inference. We’ll use a dollar cost ratio of memory bandwidth speeds.
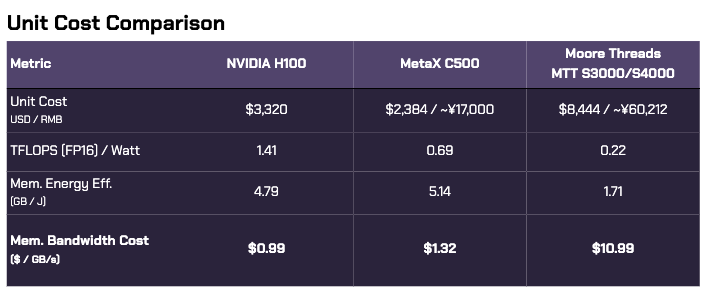
The H100 edges out the C500 in memory bandwidth ROI by a small margin, owing to its more advanced HBM3 memory stack vs. the C500’s HBM2E, though the C500 costs ~28% less to produce than the H100.44
Despite lower performance stats, the MTT data center card lineup costs more than 2.5x as much as an H100, and 11x as much on a $ / GB/s basis.
Since Moore Threads is entity-listed (and MetaX is not), its chips - despite lower performance - cost considerably more than MetaX’s competing chip line (2.5x gross, 11x worse ROI). That puts Moore Threads at a severe disadvantage on hardware alone.
This is an illustrative impact of entity listing on available process nodes to a downstream customer. Yield rates - the number of successful dies cut from a wafer divided by total potential dies - amortize the cost of wafer production over all resulting chips sold. It’s generally understood that for more advanced process nodes, SMIC yields are currently between 30-40% compared to 80-90% at TSMC. All else being equal, TSMC is able to spread its wafer production costs over twice as many chips sold as SMIC can.45
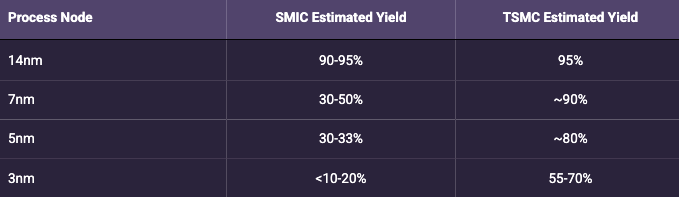
Source: Bismarck Analysis, Granite Firm, SemiWiki
A deeper-dive on the domestic logic and memory chip fabrication supply chain will be the subject of a future post.
Unintended Consequences of Myopia (UCM)
Undeniably, the lack of leading-edge HBM from foreign suppliers is hindering domestic chip competitiveness. However, there are ways around this issue. In a dramatic reveal on August 12 2025, Huawei revealed a new software tool called the Unified Cache Manager (UCM) as a way to accelerate training and inference workloads without access to HBM.46
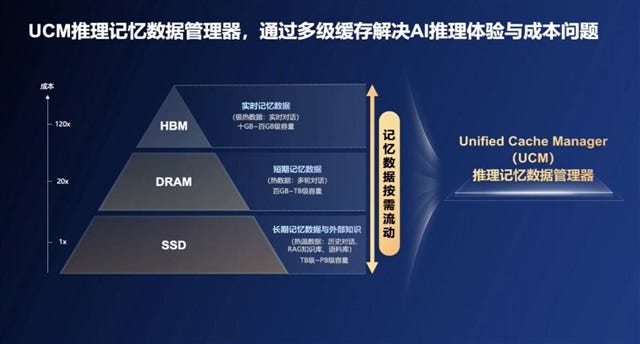
Specifically, UCM builds a three-tiered storage architecture to split up the KV cache of LLMs across different memory types:
HBM for extremely common data, accessed in real-time and at high frequency
DRAM for a balanced approach, storing data with moderate frequency
SSDs for low-frequency data. This evades the bottleneck of VRAM capacity in a chip, and accesses much cheaper, more readily available storage for low-frequency values.
This would unlock astoundingly long context windows without the need for bigger HBM - critical for reasoning models with ballooning token volumes, and overcoming the HBM denial hurdle while CXMT ramps up production.47
The net effect is a triple-purpose optimization across performance, energy, and financial costs:
First token latency is reduced by up to 90%
Sharding KV cache across multiple memory types 10x’s the inference context window
Intelligent routing of data “heat” improves tokens-per-second by 2-22x
Huawei intends to open-source UCM this month, which would provide a systemic boost to all domestic chip companies currently gated by HBM restrictions. While benefits on single cards may be nominal, supernodes (multiple-card clusters) with multiple memory types (SSDs, DRAM, SRAM) would see substantial benefits. Not to mention cloud-scale deployments.
Heterogeneous Computing
In the same way that UCM leverages relative strengths of different memory types, heterogeneous computing optimizes and distributed workloads according to the relative strengths of different chips.
Paul Triolo and I have written about advancements in heterogeneous computing in the past. I’ll simply restate that there are large-scale projects sponsored by major hyperscalers and research labs achieving better training and inference performance through heterogeneous (multiple-vendor) computing clusters than homogenous ones.

This is a key part of the Shanghai municipal government’s “AI+Manufacturing” plan - building a low-latency, distributed industrial “smart compute cloud.” Sugon - the supercomputing company recently acquired by Hygon - also recently announced a high-profile partnership with 20 other hardware companies, OEMs, and research labs, with the intent to develop and promote large-scale heterogeneous computing systems.48 Sugon has already launched a new supercluster product to demonstrate these capabilities.49

Source: Sugon WeChat channel.
“Compared with closed systems, Sugon AI super cluster system not only works as efficiently as a single computer through its tightly coupled design, but also supports multi-brand AI accelerator cards and is compatible with mainstream software ecosystems such as CUDA, providing users with more open choices and significantly reducing hardware costs and software development and adaptation costs, thus protecting initial investments.”
That excerpt from the Sugon announcement is critical. Functional heterogeneity should not just be considered in the context of entity listing and trade wars. It is an inherently anti-fragile economic paradigm that will reduce unit costs for training and inference workloads overtime.
2. Strategic Backing
Standouts: Huawei, T-HEAD, Enflame, Moore Threads
Laggards: Iluvatar CoreX, Biren
Losers: Jingjia Micro, Denglin Technology
In our analysis, government funding does not play nearly as important a role as does creating a strategic and/or financial relationship with a pre-existing hyperscaler (Tencent, Alibaba, ByteDance, etc.).
Hyperscaler or CVC partnerships can pave the way for later commercial adoption, as evidenced by the tight-knit relationship between Enflame and Tencent. While Moore Threads has the highest private valuation in the list, Enflame’s commercial adoption has been more voluminous given Tencent (and Meitu’s) endorsements.
Biren and MetaX do not have explicit hyperscaler financial backing, though both have a significant relationship with SMIC’s CVC which could mean expedited iteration cycles. However, Biren has seen an objectively slow turnaround since its entity listing in 2022.
Iluvatar CoreX and Denglin lack significant strategic backers, which may contribute to more muted adoption.
Finally, Moffett AI and InnoStar share Ant Group (and indirectly Alibaba) as a strategic backer. InnoStar also includes ByteDance and Lam Research on its capitalization table.
The “Made in China 2025” industrial policy is often cited as the blueprint for state-led “winner-picking” in high-tech sectors, semiconductors among them. In this limited analysis, that shorthand does not hold up.
First, many of these players share the same funding entities on the cap table (like the Big Fund), which eliminates any idiosyncratic advantage. Second, not all kinds of government capital in China are created equal. And third, an overly activist government presence on the executive team seems to slow things down faster than it can open doors for adoption.
Therefore it should not be taken on faith that Chinese government favorability or backing is a guarantor of success. Instead, we assign a higher weight to strategic or financial relationships with established technology incumbents. These players generally have the most sophisticated products, much faster iteration cycles, and strongest commercial adoption thus far.
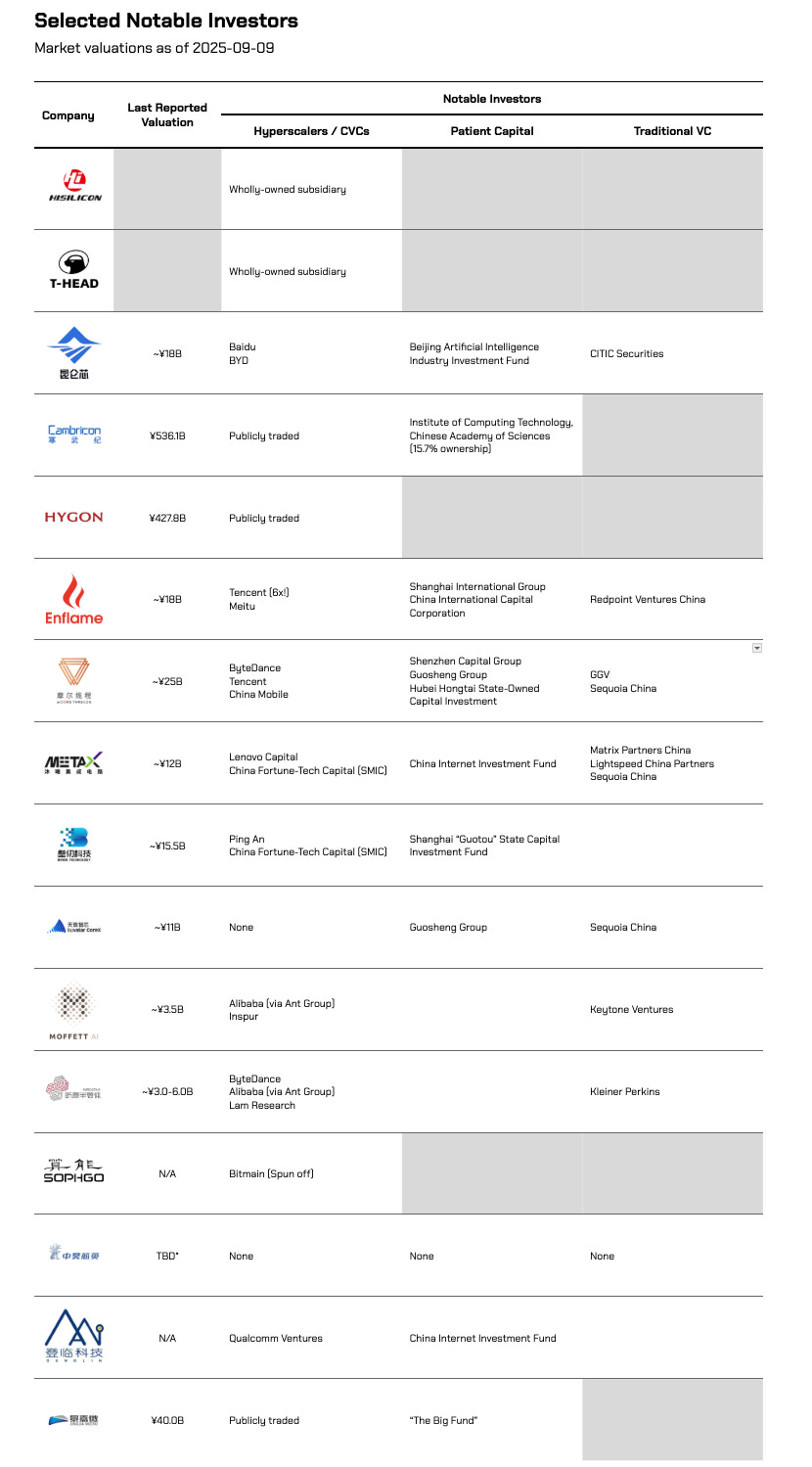
Source: Crunchbase, Bloomberg, company announcements.
* Zhonghao Xinying is navigating a potentially botched attempt to go public via reverse merger with a publicly traded tire and rubber company. Source: Tempu Co., Ltd. has faced seven consecutive inquiries from the Shanghai Stock Exchange, leading to a halt in leveraged buyouts, with funds reportedly "in transit."
The Role of “Patient Capital”
“Patient capital” is a colloquial term used to describe investment funds (typically state-connected) with much longer horizons for expected returns, usually targeting sectors deemed critical for economic growth or industrial self-sufficiency. This is not to say that profitability and ROI don’t matter, just that that is second to longer-term goals.
National Team
The national team, led by the China Integrated Circuit Industry Investment Fund (“Big Fund”), focuses on strengthening national strategic industries, filling gaps in the supply chain, and anchoring private capital around key technologies.
Financial returns are not the priority. The goal is to build industrial security.
As an example, Cambricon received early funding from the Big Fund. The company originated from the Institute of Computing Technology at the Chinese Academy of Sciences, making it a textbook case of industry-academia-research integration.
The Big Fund’s investment was both a bet on a promising semiconductor startup and an endorsement of the pathway from state laboratories to commercial application, aimed at encouraging more frontier research to be translated into market-ready products that serve national strategy.
Local Funds
Local funds, by contrast, are closely tied to regional agendas. They nurture companies that place headquarters, research centers, or production facilities in their jurisdictions in order to strengthen the local industry ecosystem and reinforce the value chain.
For example, the Shanghai IC Fund’s mission is to consolidate and expand the city’s leadership in China’s semiconductor sector by building a complete industrial cluster that spans design, manufacturing, packaging and testing. They frequently act as bridge investors, supporting promising firms in early rounds before inviting the Big Fund to co-invest, creating “national plus local” synergies.
With the support of both the Shanghai and Beijing IC funds, these two cities are emerging as distinct national leaders: Shanghai as the hub of the full semiconductor value chain with champions such as SMIC (Semiconductor Manufacturing International Corporation), AMEC (Advanced Micro-Fabrication Equipment), MetaX, and Enflame.
Beijing is establishing itself as the capital of R&D and design, represented by companies like Cambricon, Moore Threads, and Hygon.
SOE Venture Arms
SOE venture arms sit somewhere in between. They pursue some of the same financial goals as commercial vc firms, but their deeper value lies in the strategic resources they provide.
Startups gain access to procurement pipelines, pilot projects, and anchor customers within the SOE system. They also benefit from credibility and political backing that smooth the path for future fundraising, bank creditline, and government project participation.
On top of that, SOE venture arms open doors to industrial expertise, supply chain partners, and even manufacturing capacity. Unlike financial investors, they are often more patient, willing to stay with companies through multiple growth cycles.
All four of the dragons have attracted both SOE venture arms and local funds, showing how deeply these funding vehicles are embedded in the country’s industrial rise. Together, national direction, local execution, SOE backing, and corporate upgrading create a layered investment ecosystem that de-risks financing while guiding capital recipients towards real use cases and sustained demand.
Drawbacks of State-Led Innovation
Patient capital is best when passive. Companies with the strongest connections to government are actually among the worst performers.
Despite a major head start, deep connections to China Electronics Technology Group Corporation (CETC), government, and PLA contract revenues, Jingjia Micro (景嘉微) has been wholly unable to transition their product line towards AI accelerators, seeing their GPU revenues completely collapse by 40-70% YoY from 2021 to present as new competitors have come online.
While Iluvatar CoreX (another early entrant) was founded by an Oracle veteran, in 2021 they appointed Diao Shijing (刁石京), former Head of the Ministry of Industry and Information Technology, to the position. Though the company has had some success with their training card accelerator lineup, order volumes for shared heterogeneous computing projects are much smaller than competitors’ by an order of magnitude (100 inference cards vs 1000 Moore Threads GPUs, 2000 Huawei Ascend 910Bs, 3000 MetaX GPUs).50 It seems Iluvatar has had a slower time transitioning from R&D into widespread commercialization.
Hyperscaler Tagalongs
Based on the rate of commercial deployments, there seem to be two winning strategies for domestic chip designers: either you are the customer and you build it yourself (Huawei, T-HEAD, Kunlunxin), or you team up with an incumbent hyperscaler.
Even with advancements in heterogeneous computing technology, it seems far more difficult to go it alone without a close alliance to a major hyperscaler. Biren and Iluvatar CoreX, despite strong teams and early traction, have yet to see large-scale adoption in hyperscalar clouds. Jingjia Micro and Denglin Technology are completely absent from any major commercial rollouts.
It should come as no surprise that China’s hyperscalers - Huawei, Alibaba, Baidu, Tencent - have immense incentive to manage their cloud infrastructure costs, for the same reason that Western equivalents all have internal silicon teams (Meta: MTIA, Microsoft: Maia 100, Google: TPU, Amazon: Trainium/Inferentia). The first three have their own wholly-owned fabless design firms, while Tencent has facilitated close relationships with at least two little dragons, Enflame and Moore Threads, through several rounds of funding.51
This close relationship with Tencent is significantly paying off for Enflame, which is reporting the largest volume of commercial adoption for their S60 inference cards compared to other independent fabless firms. Even in the more hands-off approach that Tencent uses, it still leveraged Enflame’s expertise to co-design its custom Zixiao AI inference chip for Tencent Cloud.52
3. Leadership
Standouts: Huawei, Cambricon, Enflame, Moore Threads, MetaX.
Laggards: Biren (though initially promising, has suffered greatly from post-entity list turmoil).
“Silicon Valley DNA + Localized Innovation” is a common turn of phrase for successful company leadership. Teams with executive tenure at major SV institutions (NVIDIA and AMD especially) have some of the best performing chips, though Huawei diaspora is also quite strong.
In general, engineers leading engineers seems the clearest path to victory. Government or ministry presence in leadership is actually a major detractor from progress.
The prevailing pattern for domestic chip leaders seems to be “硅谷基因+本土化创新”, or “Silicon Valley DNA + localized innovation.” Many of the top performers in the space have executives with deep experience in Silicon Valley companies, but have been implementing those solutions in the local ecosystem.
The phrase 技而优则管 (jì ér yōu zé guǎn, literally “those whose technical skill is excellent then manage”) accurately describes the best performing companies on this list. It more or less means “promote the best engineers to lead engineers,” and is a common saying in Chinese tech circles to insist that the person running an engineering team should be an engineer, not an MBA.53
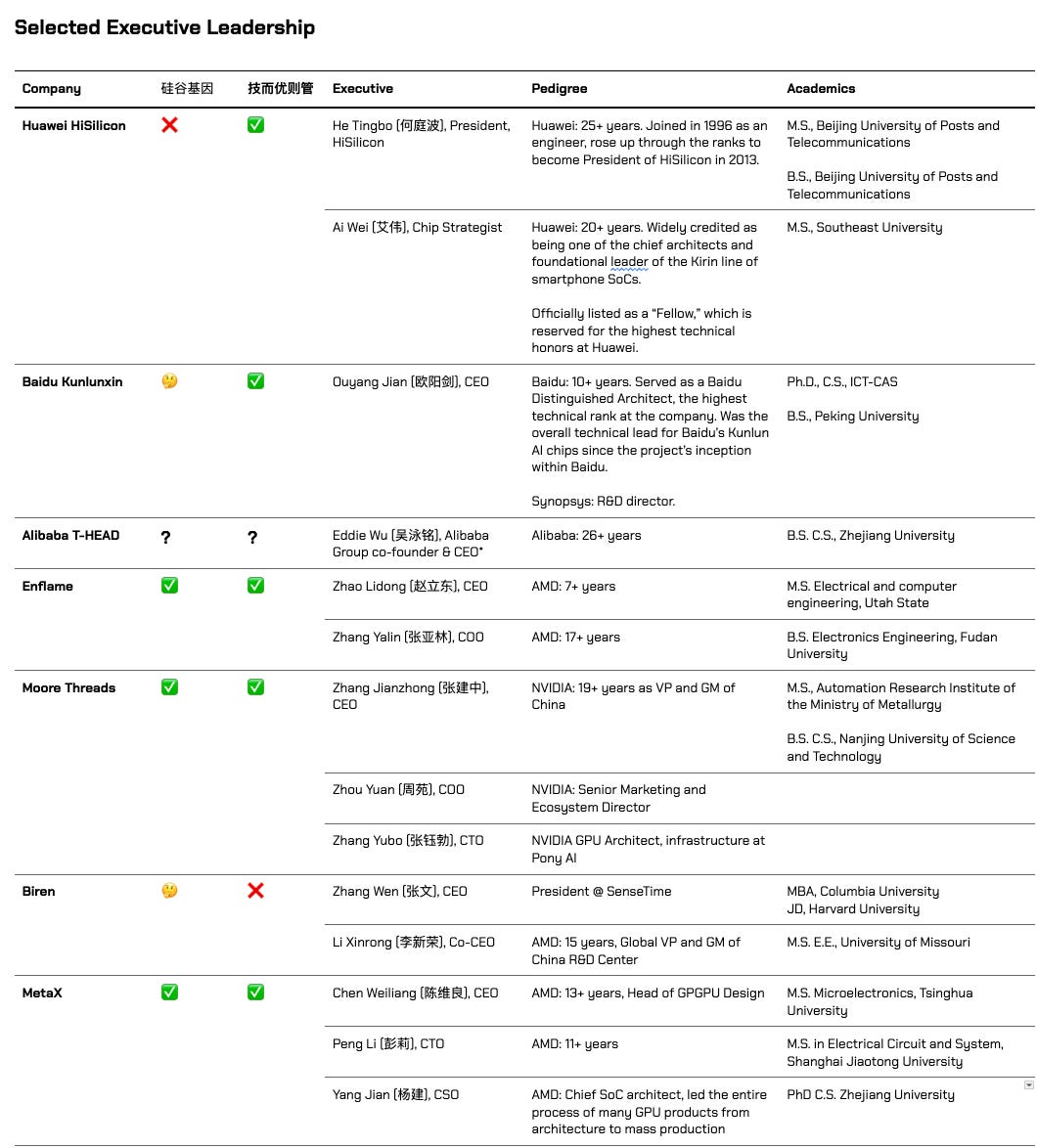
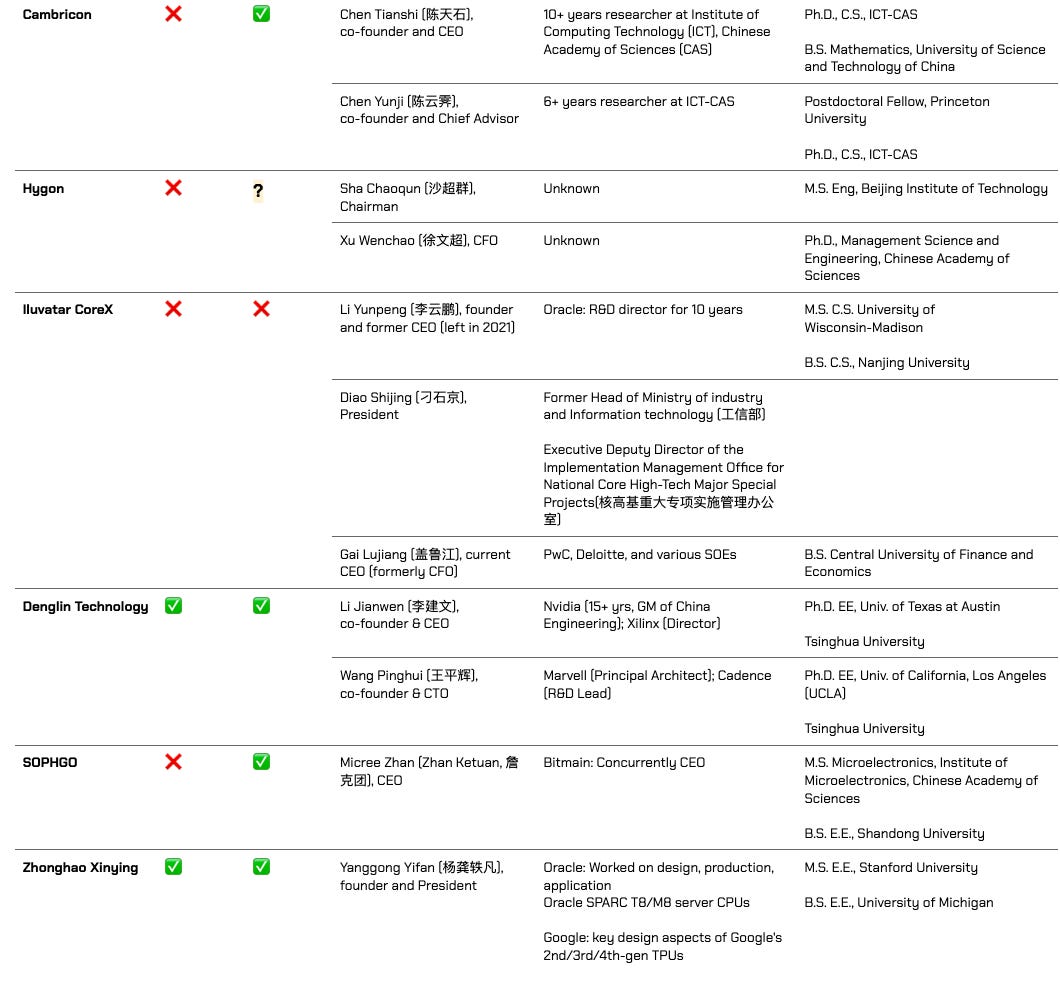
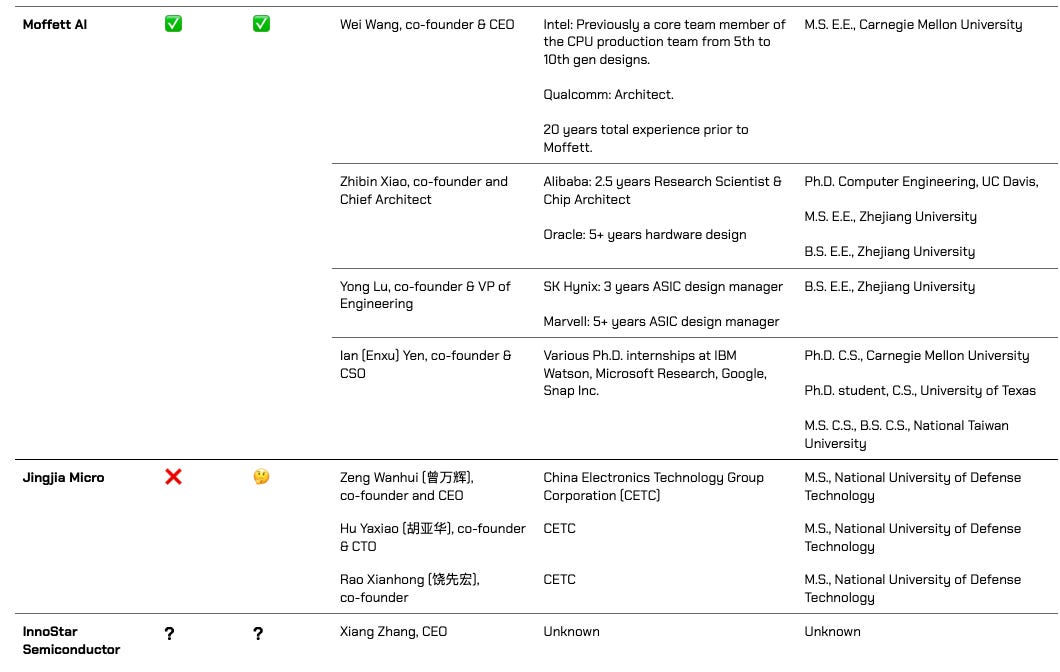
The three best performing little dragons - Enflame, Moore Threads, and MetaX - all have 硅谷基因 in founding leadership. Enflame and MetaX have decade-plus AMD veterans with a long history of working together, and Moore Threads is effectively carved out from the NVIDIA China team.
Exceptions to this rule would be among the Chinese Heavyweights, where leadership is cultivated and promoted from within, and Cambricon. Cambricon is a unique story where the two founding brothers, both STEM prodigies, were fast-tracked into a Chinese Academy of Science-sponsored ecosystem through a program for gifted youths. Their prowess in mathematics and computer architecture, along with the CAS resources at their disposal, eventually led to the founding of Cambricon out of their research into custom accelerator hardware.
Aside from that, we note that an outsized government or ministry presence on the leadership team does not seem to be associated with better product performance (no surprise) or commercial adoption. Examples here would be Iluvatar CoreX and Jingjia Micro. While government connections may seem helpful in large-scale intelligent cluster contracts, the basis for procurement seems to be more meritocratic.
4. Commercial Adoption
Standouts: Huawei, Kunlunxin, T-HEAD, Enflame, Cambricon, Hygon
Honorable Mention: SOPHGO.
The most widely supported domestic chip designers to date include all three heavyweights (HiSilicon, Kunlunxin, T-HEAD), two of the four little dragons (Enflame, Biren), both public champions (Cambricon, Hygon) and finally Iluvatar CoreX.
The Chinese hyperscaler market is dominated by the Big Three: Huawei, Tencent, and Alibaba. Baidu AI Cloud, Kingsoft Cloud, and ByteDance (Volcengine) are also notable.54 Additionally, there are the state-owned Chinese telecommunications companies China Unicom (中国联通), China Mobile (中国移动), and China Telecom (中国电信) to consider.
Alibaba is the cloud computing leader in terms of market share, and provides the richest detail on supported accelerator programming languages and hardware platforms. NVIDIA and AMD-based computing instances are supported by nearly all Chinese hyperscalers - this is not the case for its domestic chip designers.

Source: Alibaba Cloud.
Until recently Chinese telco server procurement did include solutions from NVIDIA, AMD, and Intel, but the MIIT has specifically instructed the telcos to phase out foreign processor usage by 2027, accelerated by looming export controls and a push for domestic self-sufficiency. This instruction is limited to CPUs at the moment (hitting Intel and AMD), but a similar instruction for GPUs has not been ruled out.55
The below table highlights public confirmations of domestic chip adoption in high-workload commercial sectors. The heavyweights, little dragons, and public champions dominate the upper rankings. This is not all-inclusive since there is a long tail of neoclouds that are not the subject of this analysis.
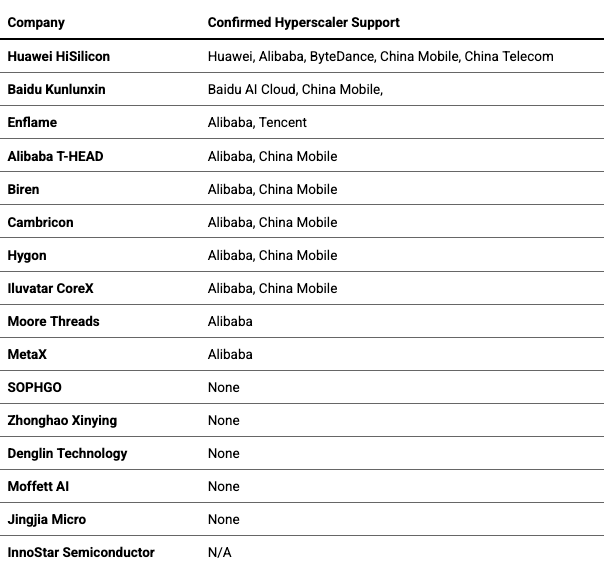
In a major order from China Mobile, Huawei’s Ascend line won over 70% of the contract, and Baidu will be supplying its Kunlunxin processor line to many systems integrators in that contract.56
Enflame has reportedly shipped over 70,000 S60 inference cards to date, mostly to Tencent computing clusters. Outside of Huawei and Cambricon, this is actually the largest recorded figure of commercial shipments for the newer entrants.57
Finally, in other cloud contracts with multiple vendors, we’ve seen comparable deployment figures for MetaX, Moore Threads, and Ascend accelerator cards in the thousands, with additional (though meager) participation from Biren and Iluvatar.
Deployment breakdowns are not always available by vendor or SKU. We’ll attempt to track shipment figures in future versions of the Silicon Vanguard dataset. For now, what we generally observe is that the Heavyweights are well-positioned given their cloud computing footprint, Enflame seems to be leading the weyr of dragons, and Cambricon + Hygon are making strides.
Ray Wang. “According to Goldman Sachs, it suggests China’s lithography progress is 20 years behind based on the roadmap position of Chinese companies and ASML.”. X (formerly Twitter). https://x.com/rwang07/status/1962440362024456616
China is 10 years behind Taiwan on chips: NSTC. (2024, October 1). Taipei Times. https://www.taipeitimes.com/News/taiwan/archives/2024/10/01/2003824622
Ezell, S. (2024, August 19). How innovative is China in semiconductors? Information Technology and Innovation Foundation. https://itif.org/publications/2024/08/19/how-innovative-is-china-in-semiconductors/
Sharwood, S. (2025, June 20). US tech Czar: China just two years behind on chip design. The Register. https://www.theregister.com/2025/06/20/china_us_chip_competition/
Jukanlosreve. China’s Answer to NVIDIA? How Struggling Cambricon Pulled Off a Dramatic Comeback [Deep Dive]. X (formerly Twitter). https://x.com/Jukanlosreve/status/1961619800427511990
Weixin_44005328. 华为UCM技术简介. CSDN博客-专业IT技术发表平台. https://blog.csdn.net/weixin_44005328/article/details/150305332
Patel, D., Kourabi, A. J., Xie, M., & Koch, J. (2025, September 8). Huawei ascend production ramp: Die banks, TSMC continued production, HBM is the bottleneck. SemiAnalysis. https://semianalysis.com/2025/09/08/huawei-ascend-production-ramp/

For more on this math, check out Tensor Economics - this will be a recurring theme in Machine Yearning and energy-compute research.
https://arxiv.org/pdf/2312.05725
Sources for table:
https://eu.36kr.com/en/p/3411091131567747
https://csi-nn2.opensource.alibaba.com/blog/deploy%20on%20th1520
https://github.com/XUANTIE-RV/csi-nn2
https://www.paddlepaddle.org.cn/documentation/docs/en/install/Tables_en.html
https://forum.cambricon.com/uploadfile/user/file/20201125/1606289569710855.pdf
https://www.usenix.org/system/files/osdi25-dong.pdf
https://docs.gpustack.ai/0.5/tutorials/running-inference-with-hygon-dcus/
https://www.alibabacloud.com/blog/ai-model-inference-service-an-overview_602002
https://www.tomshardware.com/pc-components/gpus/chinas-moore-threads-polishes-homegrown-cuda-alternative-musa-supports-porting-cuda-code-using-musify-toolkit
https://www.dramx.com/News/IC/20230614-34241.html
https://www.birentech.com/product_details/1.html
https://www.kisacoresearch.com/sites/default/files/documents/moffett_ai_s4_accelerator_datasheet.pdf
https://doc.sophgo.com/sdk-docs/v23.05.01/docs_latest_release/docs/SophonSDK_doc/en/html/sdk_intro/1_intro.html
https://www.tomshardware.com/news/chinese-gpu-developer-gets-government-funds
https://watermelonwater.tech/archives/%20Efficient%20AI%20Model%20Inference%20with%20Paddle%20Lite%20on%20JM9230%20GPU
https://www.tomshardware.com/pc-components/gpus/nvidia-bans-using-translation-layers-for-cuda-software-to-run-on-other-chips-new-restriction-apparently-targets-zluda-and-some-chinese-gpu-makers
https://sakana.ai/ai-cuda-engineer/
https://www.youtube.com/shorts/W3keOVTy2yE
https://xcoresigma.com/productinfo
https://technews.tw/2025/04/15/moore-threads-musify-toolkit-beat-cuda/
https://baike.baidu.com/item/%E5%BC%A0%E6%96%87/59985602
https://archive.md/gFn3O
https://www.sohu.com/a/803570474_121922042
https://www.birentech.com/news/118.html
https://hc34.hotchips.org/assets/program/conference/day1/GPU%20HPC/HC2022.BirenTech.MikeHong.LingjieXu.v01.pdf
https://www.federalregister.gov/documents/2023/10/19/2023-23048/entity-list-additions
https://www.bis.gov/press-release/commerce-strengthens-export-controls-restrict-chinas-capability-produce-advanced-semiconductors-military
https://www.tomshardware.com/tech-industry/chinas-cxmt-begins-mass-producing-hbm2-memory-well-ahead-of-schedule-2026-was-the-previously-telegraphed-target

https://x.com/firstadopter/status/1691877797487165443
https://www.granitefirm.com/blog/us/2022/05/13/yield-rate-comparison/
https://blog.csdn.net/weixin_44005328/article/details/150305332
The literal translation for the tool - “推理记忆数据管理器” (“Reasoning Memory Data Manager”) all but confirms it’s intended to meet the needs of these new workloads.
https://mp.weixin.qq.com/s/HHh0kXdOC8EkDDm7HLEiEA
https://mp.weixin.qq.com/s/069VzI0wd9FJRKh9H4Bq_Q
https://www.scmp.com/tech/tech-war/article/3276213/chinas-nvidia-wannabe-tencent-backed-ai-chip-start-enflame-flags-ipo-intention
https://www.reuters.com/technology/tencent-backed-ai-chip-startup-enflame-raises-27-bln-state-linked-investors-2023-09-28/
https://www.cyjiaomu.com/article/f26di This is a deliberate twist on an older saying, 学而优则仕 (xué ér yōu zé shì, literally “those who excel at study become officials”).
https://www.yicaiglobal.com/news/bytedances-volcano-engine-starts-price-war-in-chinas-enterprise-llms-sector
https://mp.weixin.qq.com/s?__biz=MjM5OTM2NjgxMw==&mid=2652667795&idx=4&sn=f587658582fce8b5902de822c184a880&chksm=bd0f0d5e6112154b313ac48c832e5418e3373f2ad173140649197158ae097d372cf185f656b3#rd
https://www.reuters.com/technology/baidu-chip-design-unit-kunlunxin-wins-over-139-million-orders-china-mobile-2025-08-22/
https://www.eet-china.com/news/202507309451.html
Great stuff Ryan, and soooo much better than any of the other ideologically tinged "analysis" from the usual suspects and China podcasts.. great working with you on these issues...
Great overview! Looking forward to the next parts!