

Energy-Compute Theory: China's New Objective Function
The first principles playbook for the new economy

So, GPT-5 was released a few days ago.
Anyway, back to Machine Yearning, where every week is infrastructure week.
Last week, Paul Triolo and I went on the Sinica Podcast with to tell Kaiser what we saw at Shanghai’s World AI Conference.
In it, I mentioned one of the keynote speeches at WAIC by Professor Wang Yu (汪玉), Chairman of the Department of Electrical Engineering at Tsinghua University, who laid out the blueprint for his philosophy towards AI infrastructure development.
I also talked about my investment philosophy - an emerging framework called “watt-to-bit” in some fringe Western investor circles.
Turns out, China’s consensus AI strategy is mapping precisely to this investment doctrine. So it’s probably time we pull back the curtain on it.
In this week’s post, I’ll cover:
The What: Introduce Energy-Compute Theory and its primary inputs
The How:
Dissect Professor Wang Yu’s keynote as an application of energy-compute theory
Identify implications for model and semiconductor development
The Why:
Assess conditions for AI’s diffusion into the Chinese economy
Lay out the implications for both China and US AI ecosystems
Key Takeaways to Expect
Energy is the constraint: Watts are the ultimate scarce resource; compute capacity and intelligence output scale with how efficiently energy is converted into tokens.
China’s objective function: China is explicitly reframing AI and industrial policy around energy-compute optimization, treating it as a physics-based equation rather than a vague race for “AI leadership.”
A first-principles playbook: Grounding strategy in watts, tokens, and physics creates a clearer, more durable framework for competing in the new economy.
The West’s blind spot: U.S. narratives fixate on talent, chips, or qualitative intelligence thresholds, ignoring the underlying energy-compute substrate.
Winning advantage: Nations and firms that master energy-compute efficiency will dominate AI capability, industrial output, and ultimately geopolitical power.

Watts and Bits
Watt-to-bit frameworks merge power generation, storage, compute, cooling, and other AI infrastructure into a single asset class: “energy-compute infrastructure.”
Maximizing ROI with energy-compute infrastructure requires optimizing models and hardware along a 2-dimensional plane of intelligence throughput (tokens-per-second) and energy inputs (power), rather than strictly deploying the best models or chips.
This is not yet a mainstream philosophy in Silicon Valley group chats. Today, most Westerners are “scale-pilled”, meaning our prevailing strategy is to throw as many resources at a compute problem as possible, assume that the model will disproportionately improve, and the earliest movers will capture most of the profits, justifying incredibly high sticker prices.1
“Resources” in this context could mean data, chips, capital, or even talent (see “The Sovereign AI Trap” in my previous post on DeepSeek).2

Common refrains of this strategy are the Blitzscaling playbooks of the preceding tech boom and Sam Altman’s famous call to action to “capture the light cone of all future value in the universe” via AGI.34 The latter is probably the most literal interpretation of the leading sector innovation strategy Jeffrey Ding argues against in his debut book, “Technology and the Rise of Great Powers.”5
I’m an accelerationist, but scale-pilled thinking is a memetic hazard. It dangerously restrains intellectual and industrial discourse to a Thucydides Trap6 where the “race to AGI” must be won by any means… without an empirical measure for what success means in the first place.
Also, it’s abundantly clear that the Chinese AI ecosystem doesn’t operate on that paradigm anyway.
Introducing Energy-Compute Theory
This isn’t a treatise or an econ lecture. It’s just a quick intro to energy-compute theory as I’ve been drafting it - an “efficiency-pilled” counter to the “scale-pilled” doctrine dominating accelerationist dialogue. It’s also a work in progress as my investment theses evolve overtime.
🫘 BeanChina vs. BeanUSA
Imagine two rival coffee shop chains, BeanChina and BeanUSA. Every day they try to deliver as many high-quality lattes as possible. Both stores have 3 levers they can pull, and are subject to a quality constraint.
Number of espresso machines on the counter. More machines = more cups you can produce simultaneously. It also means more energy.
Energy per machine. Machines with higher power ratings can generally brew faster, serving more customers.
Shots per bag of beans. How many shots you’re able to stretch out of a given bean quantity.
Taste score the barista must hit. This is your minimum flavor standard. Drinks below this quality won’t sell. Tastier drinks can be more expensive.

Throughput
The stores pursue different strategies:
BeanUSA’s top-of-the-line H200 coffee-makers can process 4.8 units of coffee slurry per second, but the store uses a two-shot-per-lattee recipe. Its lattes are generally rated as tastier - a 9/10 on the scale. The H200 coffee-makers cost $35,000 each and have a 3 year useful life.7
BeanChina’s H20 coffee-makers are a bit less powerful at 4.0 units per second, but they buy slightly better grinders and experiment with single-shot recipes that customers still rate at least 8/10. The H20s cost $14,000 each and have a 3 year useful life. Additionally, BeanChina has ~40% cheaper power on its side of the street. 8
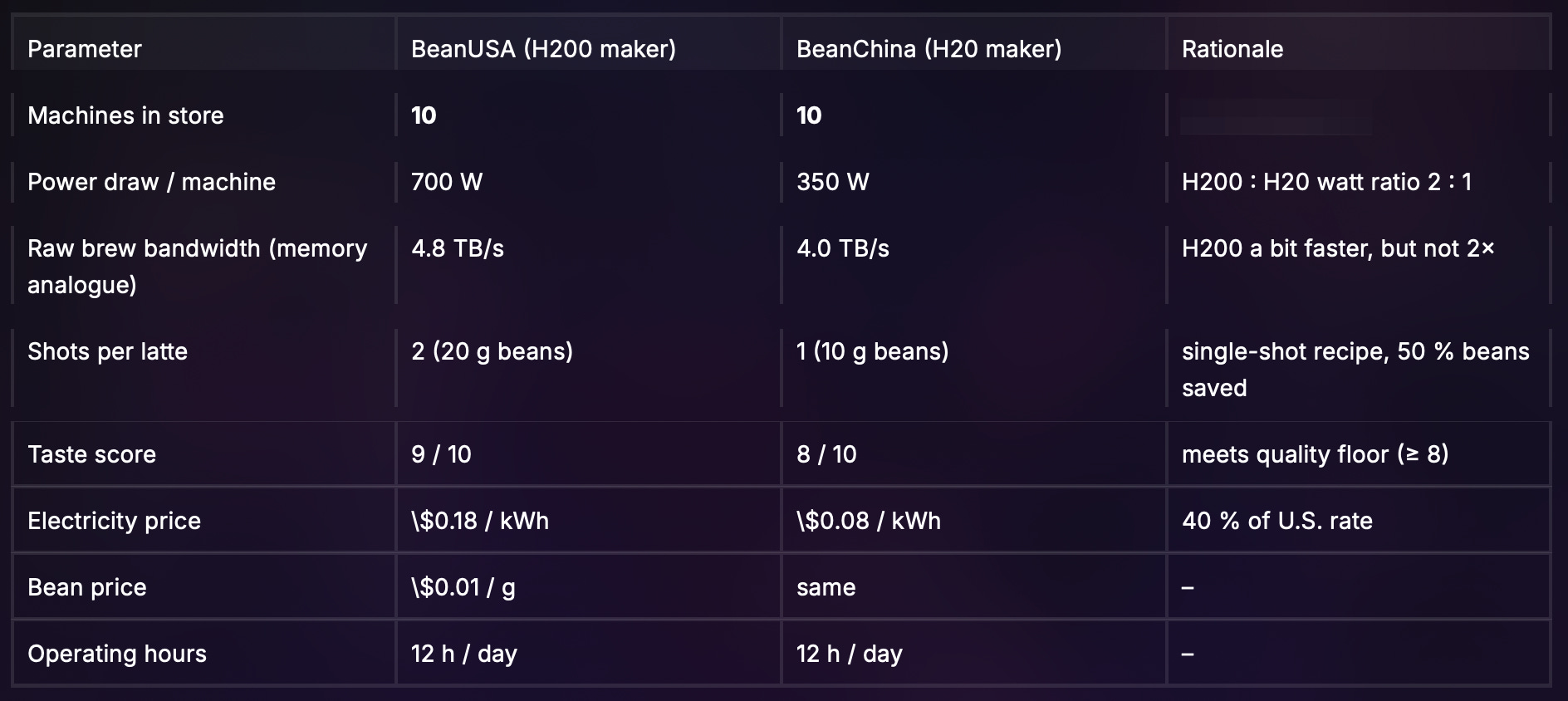
Given the above, we estimate their respective throughputs at 60 cups (BeanUSA) and 100 cups (BeanChina) per-machine-hour. With cups per hour as brewing bandwidth ÷ (shots per latte):

Even with slower silicon in their coffee-makers, BeanChina can still serve ~67% more lattes per machine than BeanUSA.
Daily P&L
Now let’s see what that looks like on an income statement:
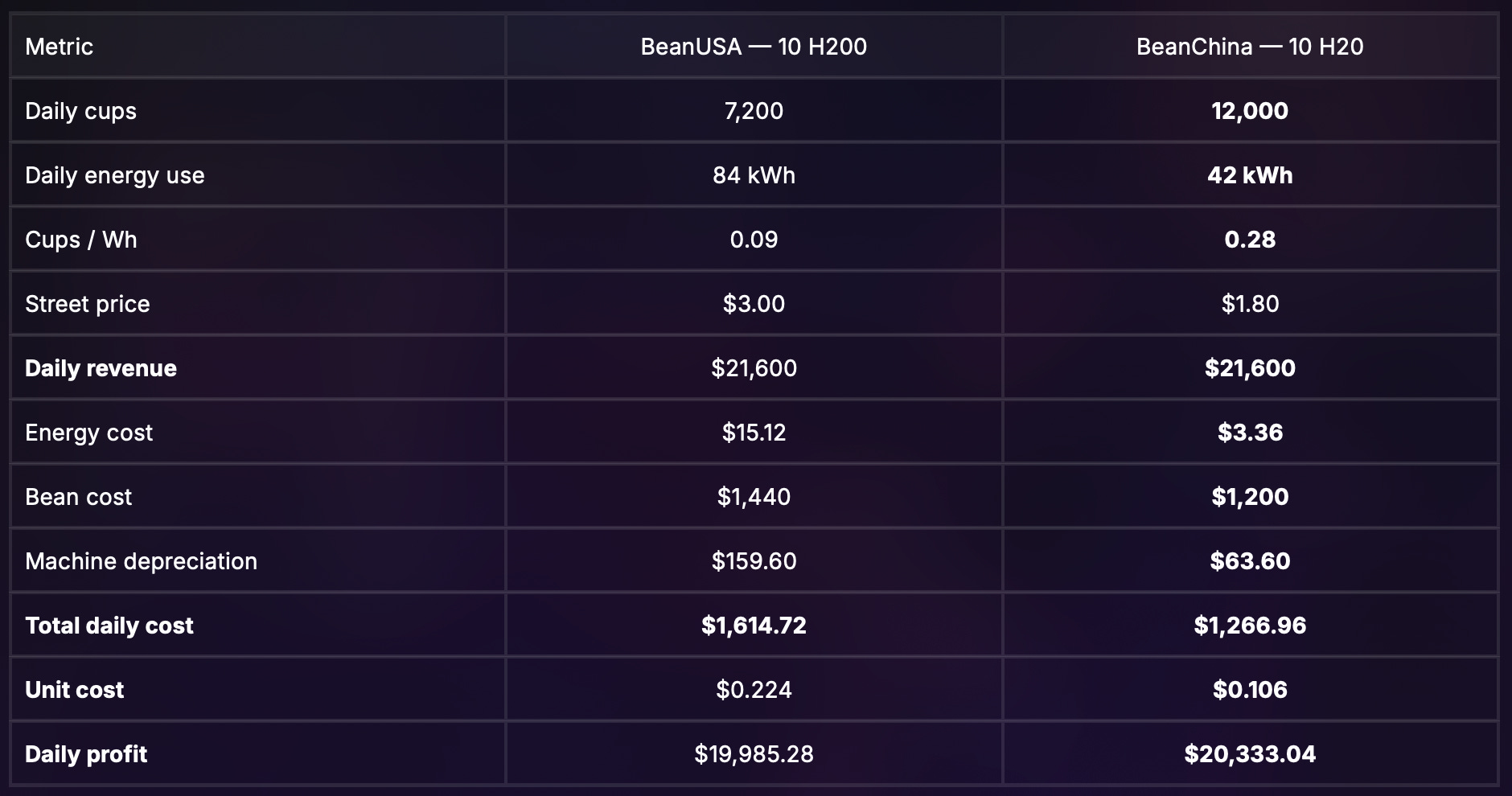
BeanChina sells ~70% more lattes, while its energy cost per cup is ~3.3× lower (0.28 cups per watt-hour vs. 0.09 cups per watt-hour), and its all-in cost per cup is roughly half of BeanUSA’s - even though the drink scores just one point lower on taste.
Corporate Innovation
BeanChina charges less per cup than BeanUSA, but makes virtually the same amount of profit.9 BeanChina invests the margin into one of three options:
Efficiency gains. R&D for much denser bean variants. Further grinder technique refinements. At best, BeanChina now only needs 7 grams of beans per cup - and early taste tests indicate their lattes are even tastier than before.
More machines. A linear increase to throughput.
Hybrid strategy. A combination of greater per-cup efficiency and volume increase.
BeanUSA tries to make up for this by buying more of its H200 coffee-makers, but without changing the underlying recipe, their unit costs remain the same.
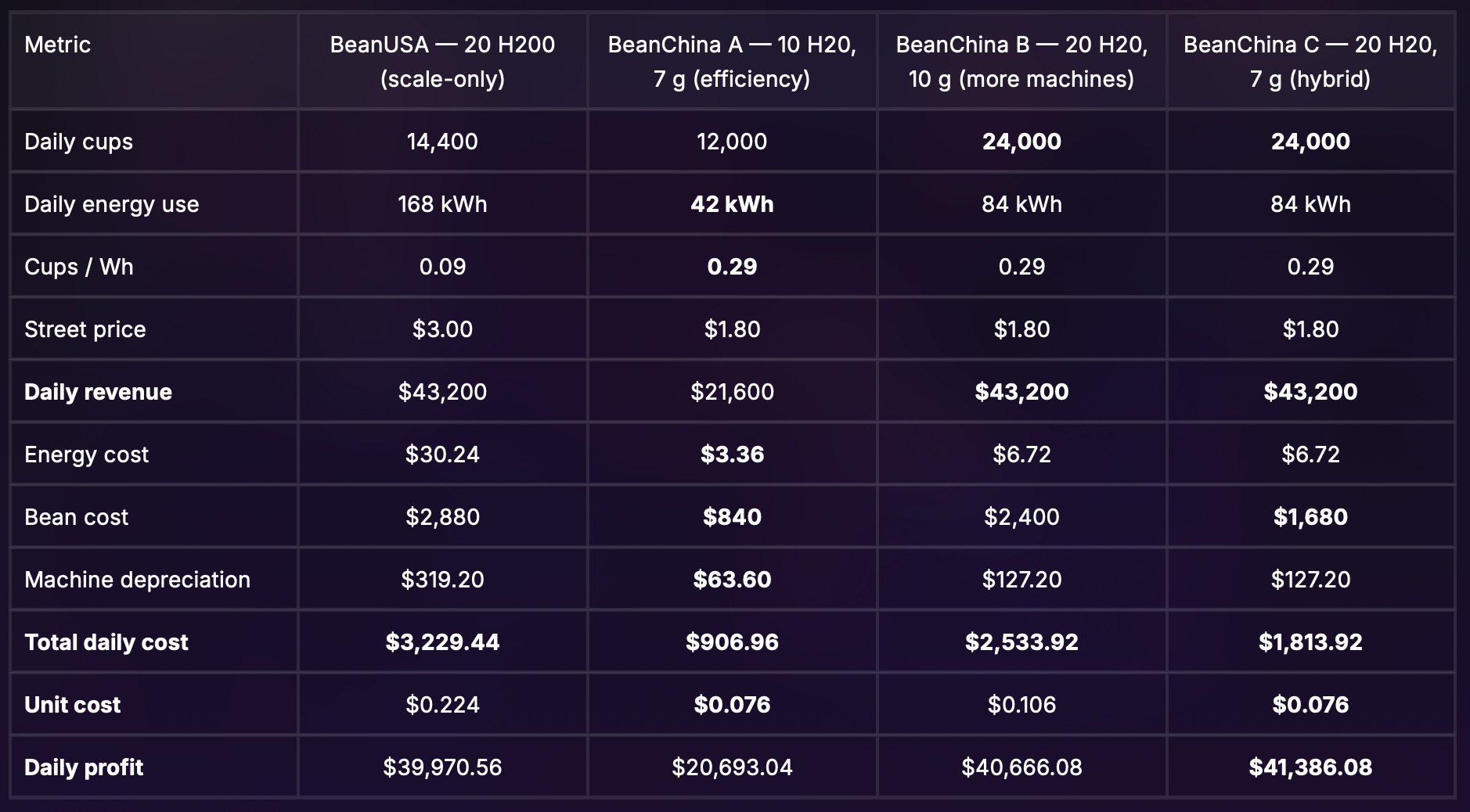
After the investments in bean R&D, BeanChina maintains its energy cost per cup advantage, while simultaneously reducing bean costs. Unit costs are now just 34% of BeanUSA’s.
In strats B and C, the two stores are still making roughly the same amount of profit, but BeanUSA had to shell out $350K in upfront capital to do it - $210K more than BeanChina’s incremental capex.
The DeepBean Price War
Finally, BeanChina’s scientists unveil a new recipe, the DeepBean-R1, which is rated as slightly tastier than BeanUSA’s most popular brew: a 9.2/10. And what’s more, DeepBean-R1 is available for just $2.25 / cup vs. BeanUSA’s $3.00.
Curious customers swamp BeanChina’s counters, and BeanUSA panics, slashing its own price to $2.25 while scrambling for a new recipe.10
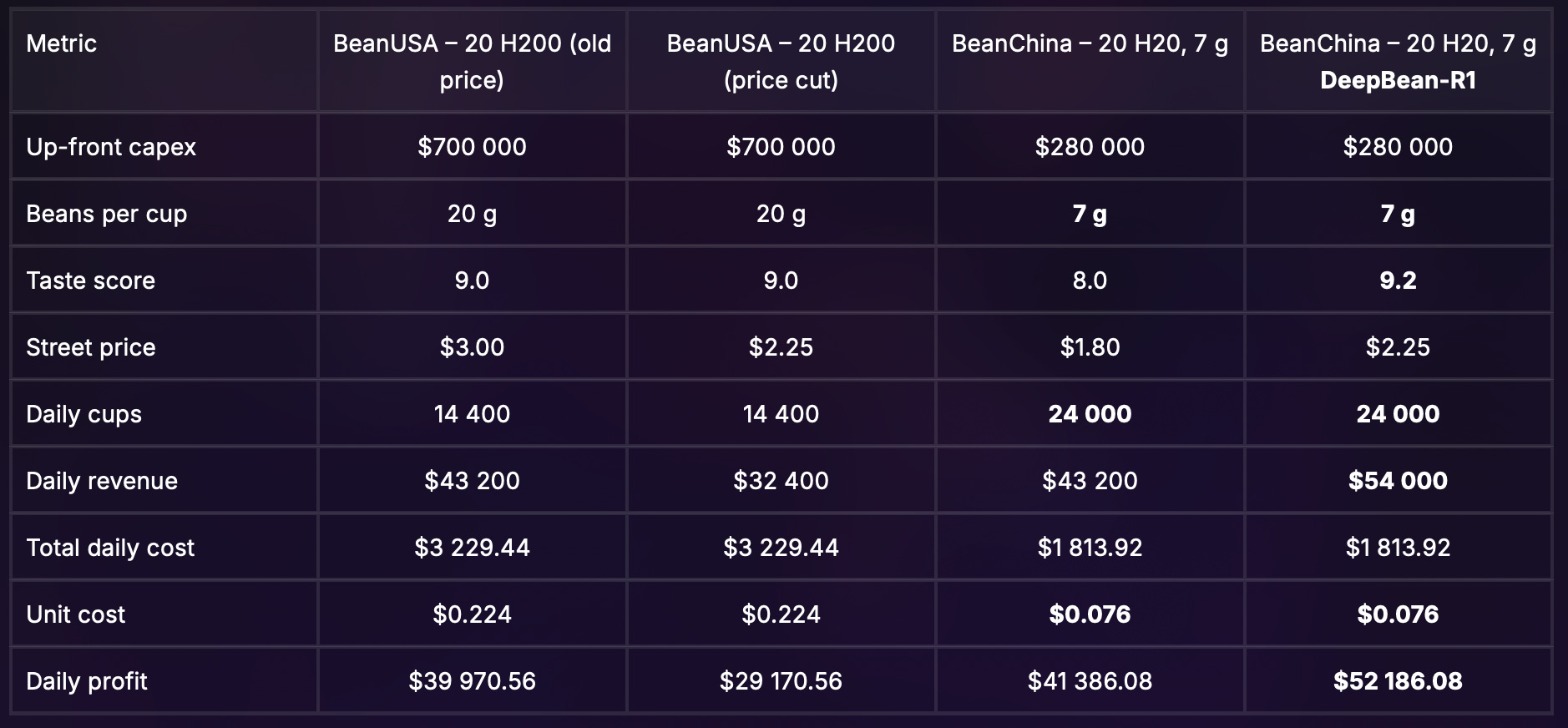
BeanUSA’s daily profit drops by about $11K. BeanChina now clears $52K, a gap of $23K despite only spending 40% of BeanUSA’s capex.
🥤 Takeaways
BeanChina might have started at a disadvantage on machines and taste, but several key investments helped close the gap:
Scarcity-driven innovation. Invested in key efficiency gains (the single-shot recipe, finer grinders) which materially lowered both their energy cost per bean, and the beans required per cup.
Reinvestment in R&D. Overtime, investments in bean engineering yielded material improvements to taste that closed the quality gap with BeanPT-5 on a much lower cost basis.
Energy abundance. Greater energy abundance on the China side of the street meant both lower energy costs and more power available for coffee-makers. BeanChina has plenty of runway to expand to larger store footprints.
In response, BeanUSA tried to maintain its lead by buying more coffee-makers. But starting from a higher cost basis put them at a long-term disadvantage, especially once BeanChina closed the quality gap and started a price war. BeanUSA is speeding up their recipe development cycle, but is now in a defensive position.
This is energy-compute theory in a nutshell.11
Doctrine
Energy-compute theory prioritizes the diffusion of valuable, affordable intelligence into sectors of the economy where those qualities are paramount for adoption.
Value is determined by human-level performance (e.g. tasks completed) at or above a pre-determined quality constraint (yield, defect rate, MCAT score)
Affordability is determined by energy efficiency (e.g. FLOPS / Watt, tokens / joule) as a proxy for cost. Importantly, we use physical energy units rather than fiat currency units to remove noise from market saturation, trade policies, or general animal spirits.
Empiricism
In plain English, your objective is to maximize valuable intelligence per energy unit, subject to a minimum IQ score and token throughput speed.
Here’s how we capture those values and constraints:
Where, for a given combination of model(s), chip(s), and cooling infrastructure:
E = compute budget in joules (e.g. 1 megawatt-hour = 3.6 x 10^9 joules)
eta = token efficiency (tokens per joule). This is a combination metric which is based on the specs of your model and the chip it’s deployed on.
S = your time conversion factor, in this case seconds to days
Q = model intelligence (e.g. MMLU, HLE, GPQA-diamond scores)
Q_min = model intelligence threshold (defined as GPT-4o equivalent, DeepSeek-V3 equivalent, Llama 2 7B equivalent, etc. on some task-defined benchmark)
tau_sec = real-time token throughput (tokens per second)
tau_sec,min = Some throughput SLA (e.g. median 100 tokens / second in production)
Let’s break out each of those pieces.
Power (E)
This one is easy. What is your total budget of power over time (watt-hours, joules) for your compute load? This can be scaled up to a national level (a country’s total datacenter terawatt-hours per year)12, down to individual units (a Tesla Optimus 2.3kWh battery)13, or even at Kardashev scales (Type II civilizations = 4 x 10^26 watts, the total luminosity of our sun).14
Efficiency (eta)
Efficiency is derived from calculating token throughput of a given model-chip combination (tokens / second), subject to the total envelope of power for the hardware and cooling infrastructure. Using our coffee example, this is a combination of the coffee slurry your machine can process per second, and the beans required per cup.
Why does this matter? If you have a limited power budget - whether for edge robotics or a single data center - your output potential is governed by your token throughput on that budget. That could be revenue and breakeven prices if you’re a neocloud, or task completions if you’re a robot.
Fortunately, all model-chip deployment combinations can derive these values, provided you have the requisite specs. A recent survey from researchers at Shanghai Jiao Tong University found a range of energy efficiency values for different deployment combinations of 7B models, from 0.0167 tokens/J at the low end to as high as 46.66 tokens/J.15
Those highest values, deployed on PIM/NDP hardware, are no slouches on throughput speed either, achieving 481 to 1998 tokens/sec on a modest 12 to 43 watt power budget - see below.
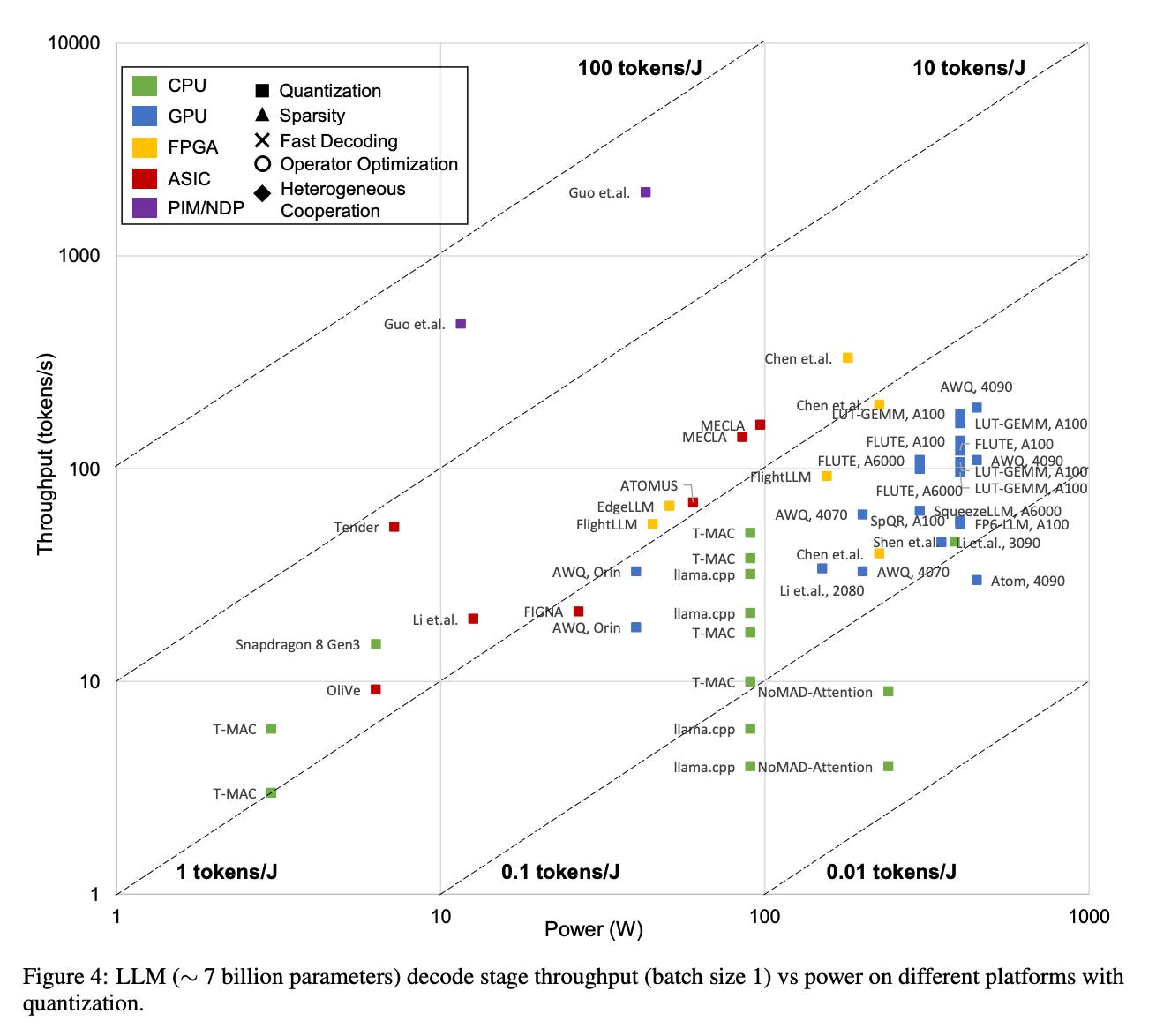
You’ll notice that clusters of different hardware types - FPGAs, ASICs, PIM/NDP - are shifting upwards and to the left on this chart, compared to the left-skewed distribution of GPU values.
There are physical limits to how much power can be deployed into a single chip governed by its thermal resistance and offtake from cooling equipment. Since nearly all energy into a chip is converted into heat, past a certain point, the chip will literally melt.16
So yielding better performance-per-chip as we approach that thermal wall is of critical importance.
Investing in different combinations of model and chip designs can greatly influence the affordability of your energy-compute infrastructure.
Intelligence (Q, Qmin)
But suppose you didn’t want just a 7B parameter model. Suppose you wanted GPT-4o or DeepSeek-V3, with hundreds of billions of parameters?
The above chart keeps model intelligence (Q) constant but varies the hardware to create efficiency frontiers. All else equal, larger and more intelligent models require more storage and more power to run, so you can’t just compare efficiency values - they must be subject to IQ constraints.
A small model might be fine for some tasks, and insufficient for others. This depends entirely on the context in which the model is deployed. That context determines your Qmin, the minimum acceptable IQ threshold.
Generally speaking, Qmin negatively impacts energy efficiency. Memory footprints for larger models influence the size of the chips required to store them (more VRAM), and the computational load of inference operations (arithmetic intensity, or operations-per-byte).
Model architectural and inference advancements like sparsity, quantization, fast decoding, and more can significantly reduce your memory footprint and arithmetic intensity, letting you compress more capable models into smaller, more energy-efficient footprints.
Investments in all of these areas influence the value of your energy-compute infrastructure.
Constraints (tau_sec, tau_sec,min)
Human conversation and reading speeds typically fall between 4 and 8 tokens per second.17 That might be enough for basic chat, but it’s not a material improvement for productivity use cases. This is even more pronounced with reasoning models, which spend 10x more tokens “thinking” about their response before issuing a verdict.18
If an inference deployment wants the model to be considered useful, especially if the target for time between chat turns is between 240ms and 760ms, you need to significantly overshoot typical reading speeds.19 Artificial Analysis pegs some of the top performing API endpoints at a median of 100 to 500 tokens / second or greater.20
Furthermore, the longer your model takes to generate a response, the more energy (watt-seconds, joules) is being used in that response.
These constraints jointly govern perceived value and affordability of your energy-compute infrastructure.
An Efficiency-Pilled Ecosystem
With that summed up, let’s jump in to how the China AI ecosystem seems to be applying energy-compute theory at scale. The keynote speeches for the Shanghai State-Owned Capital Investment (SSCI) forum were live-streamed via the conference mobile app, so I was able to get the raw files, transcribe, and translate them while I was in-country.
What follows isn’t a one-for-one translation of the slide, nor is it all the slides. It’s just a narrative voiceover of what’s being discussed. Some of my translations might be off, so please correct me if I’m way off base on something.
China’s new objective function
In his keynote, and supported by several other speakers in the SSCI (Shanghai State-Owned Capital Investment) forum, Prof. Yu lays out his vision for breaking free of one-dimensional thinking - reframing the goal from “race to AGI” to “ubiquitous edge intelligence for applications” (泛端侧智能应用 - fàn duān cè zhìnéng yìngyòng).21
To achieve this, Prof. Yu calls for merging intelligence capability and accessibility into a single objective function: maximizing inference energy efficiency subject to a given IQ threshold. That IQ constraint guarantees we are focused on what Prof. Yu calls “high quality (高质量 - gāo zhìliàng) tokens.”
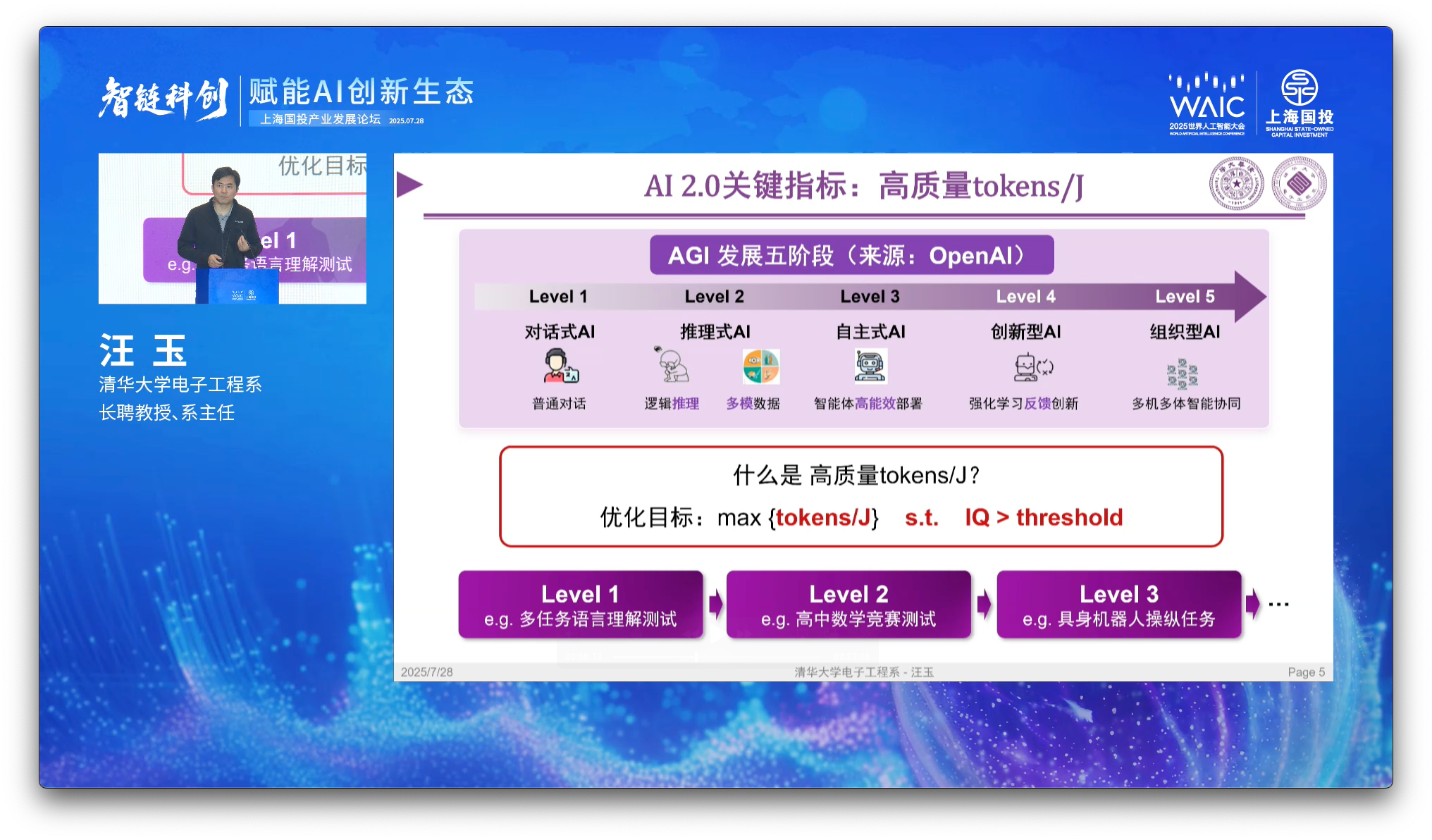
Prof. Yu explains that typical energy efficiency metrics for hardware - like FLOPS per watt, or OPS per watt - do not appropriately capture this tradeoff.
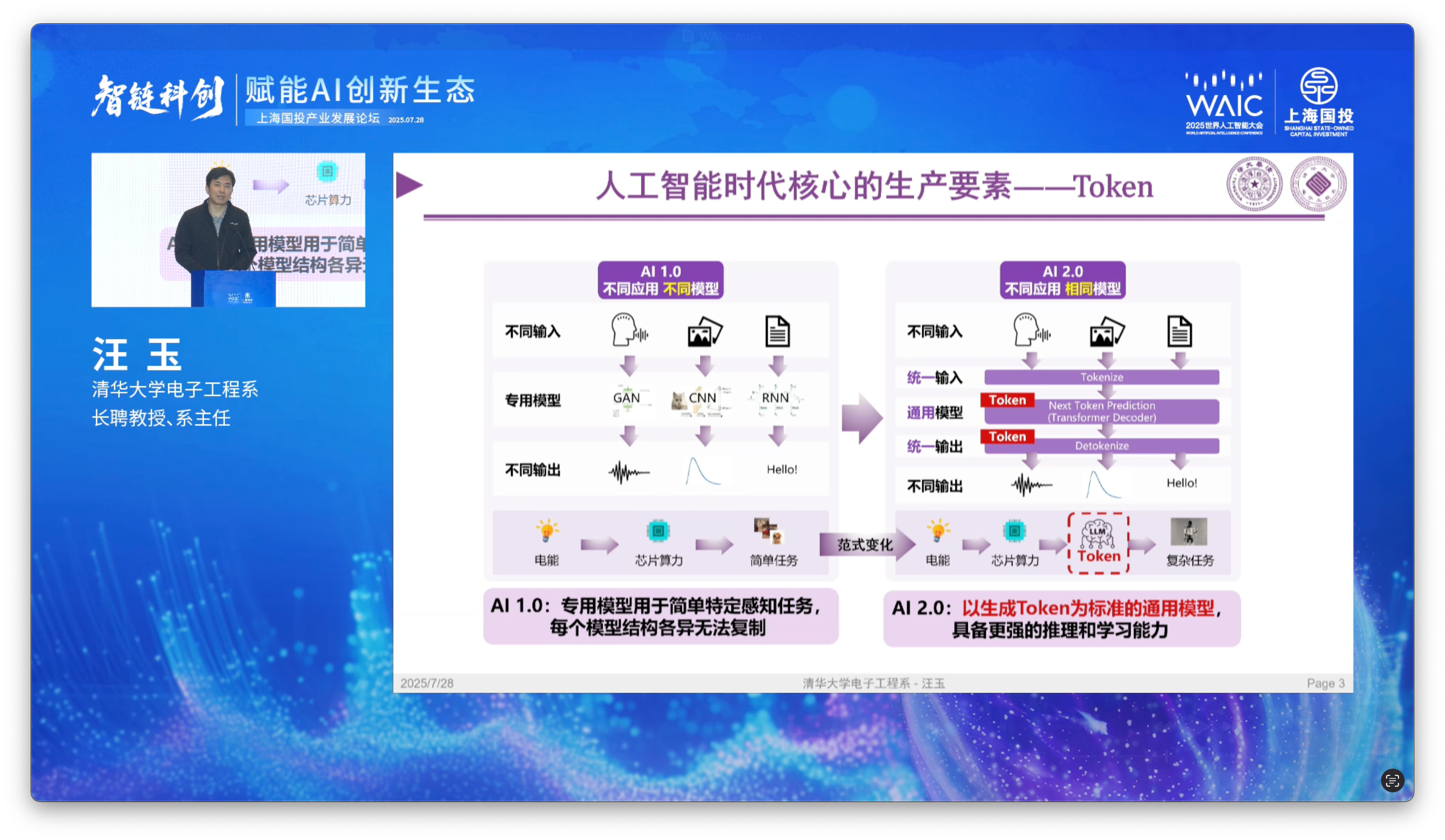
In the AI 1.0 era, speech, images, and text were stored in various kinds of data formats, which made comparative performance for hardware and models difficult to measure
In the AI 2.0 era however, newer multi-modal models are capable of converting all kinds of data inputs into tokens, then reformulating the problem into a next-token-prediction challenge
Prof. Yu calls the token the “core production factor” in the era of artificial intelligence. (核心的生产要素 - héxīn de shēngchǎn yàosù).
Tokens are more generalizable than OPS for modern machine learning applications
They can be used to represent all kinds of encoded information - pixels, code, language, conditional motion sequences (see Waymo)22, and so on
As the core production factor, developers care greatly about our systems’ ability to generate these quickly and efficiently.
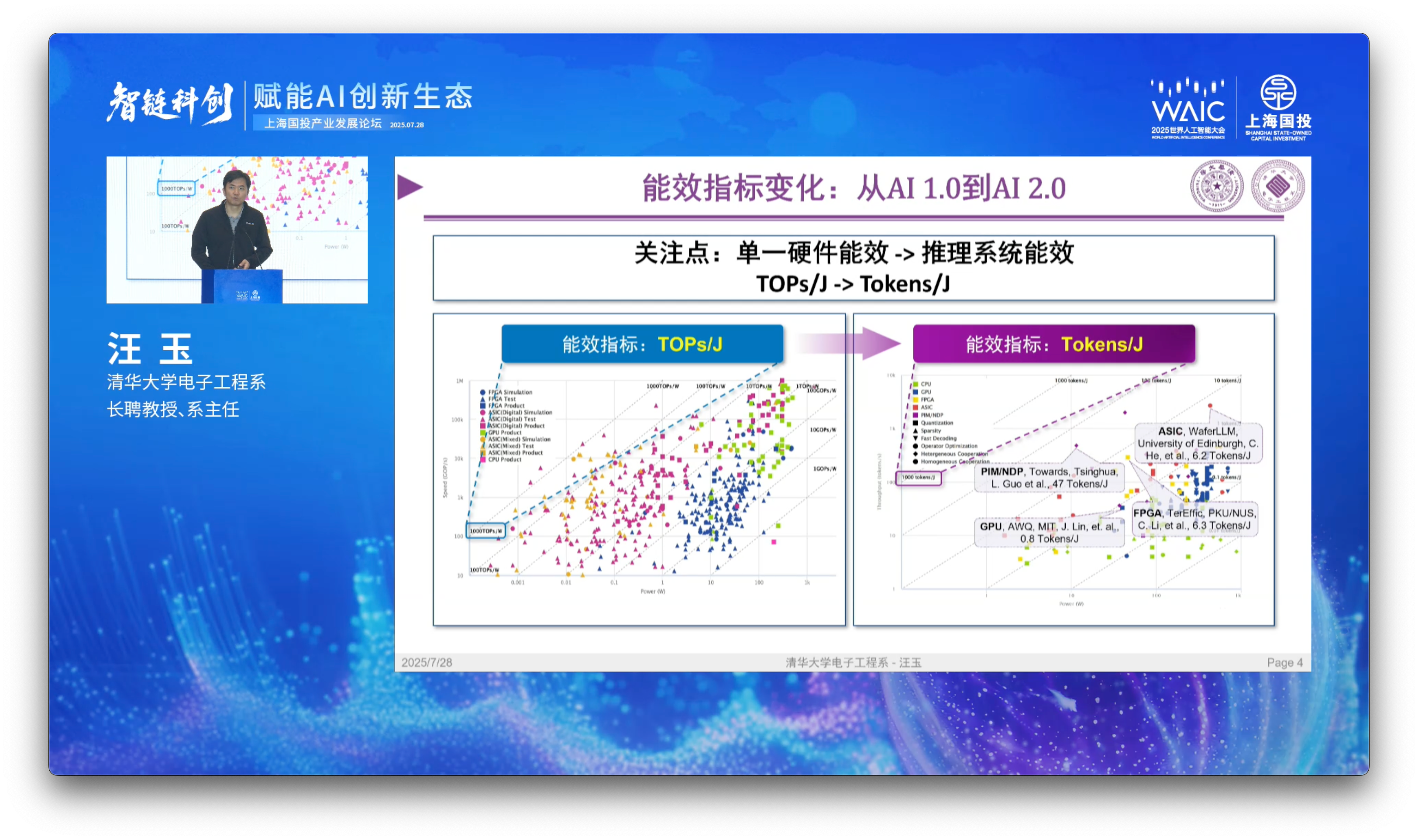
Generating tokens requires energy. So let’s next assess our energy efficiency requirements (能效需求 - néngxiào xūqiú) across different intelligence levels.
According to Prof. Yu, he pre-defines target requirement zones (需求区域 - xūqiú qūyù) in green polygons for efficiency targets in each intelligence level.
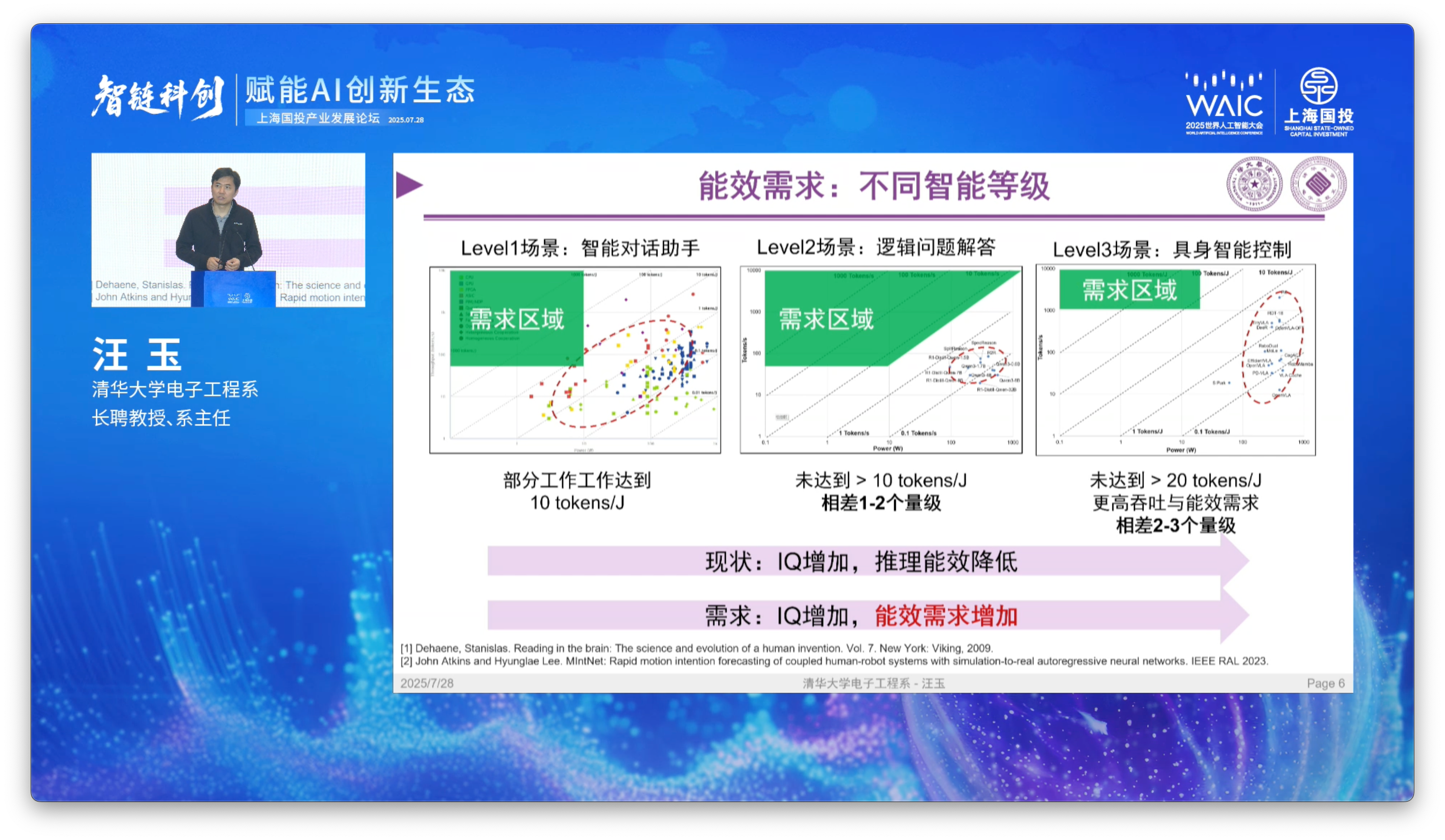
Level 1 Intelligence: Intelligent chatbots (智能对话助手 - zhìnéng duìhuà zhùshǒu). Some systems have been able to break the target zone, hitting 10 tokens / joule. So we’re making progress there.
Level 2 Intelligence: Logical question-answering (逻辑问题解答 - luójí wèntí jiědá). No systems, which include various configurations of Qwen-3 and DeepSeek-R1 models (the text is hard to make out) at this point have been able to breach the target eta of >10 tokens / joule. In fact, we’re actually 1 to 2 orders of magnitude outside the target area.
Level 3 Intelligence: Embodied AI systems (具身智能控制 - jù shēn zhìnéng kòngzhì). This is the realm of robotics deployments and visual-language-action (VLA) models. Here, the target area is further restricted to 20 tokens / joule, due to higher throughput (吞吐 - tūntǔ) and energy efficiency requirements. Currently, we’re even further behind in this realm, by 2-3 orders of magnitude off in energy efficiency.
This brings up a key challenge in energy-compute theory: currently, as IQ requirements increase, your inference energy efficiency decreases. But our energy efficiency requirements actually increase as we ascend the intelligence curve.
So how can we solve these two conflicting equations?
Robotics as an energy-compute problem
Prof. Yu asks the audience to consider the challenge of mobile robotics. A mobile robot does not have access to wired power, and cannot offload more complex queries to a centralized, larger model. Like humans, it must be able to think on the fly within a limited energy envelope.
Background
Power limits chips, chips limit memory and computational throughput, which limits token throughput. If we want robots to perform well in industrial environments (20+ hour operations), and current battery tech constrains unit lifecycles to 0.9 to 2.3 kilowatt-hours23 (3.2 to 8.3 megajoules), we need to think critically about how to allocate that energy budget in computations.
At best, with an energy-efficiency rating of 5 tokens per joule, an 8 MJ (think Tesla Optimus) form factor would have a budget of 40M tokens to process on a single charge, not accounting for idle power, locomotion, etc..
Given typical consumption of ~50K tokens for a reasoning run with thinking turned off, you might get 800 tasks completed with a reasoning model. Visual tokens are processed differently than text, but let’s simplify and avoid that for now.
Versus 500K to 2.5M tokens for end-to-end reasoning with thinking turned on, you may only get ~20 to 80 truly complex tasks completed in that budget.24
Speed is also a factor - robots must be able to not only think through the task, but complete it quickly. Is that range of completed tasks in a given power envelope faster or slower than human-level performance in an equivalent workday?
Modeling
Let’s reframe this in the form of an energy-compute problem. Assuming:
You’d only require a single VLA query per task (“What are my instructions for placing this box on the shelf”)
Subject to the following constraints:
Energy used cannot exceed your energy budget
Tasks completed must meet or exceed human-level performance in the same time period
Your task completion ceiling is the lesser of your token budget and your wall-clock time.

Results
Without getting too much further into the weeds, Prof. Yu assumes that ~100-1000 tokens/sec throughput is about the baseline (tau_sec,min) for useful embodied AI systems. That’s not a problem for well-designed cloud systems - 8 H20s can run full-blooded DeepSeek R1 at up to 8,000 tokens/sec - but today, decent models on edge hardware achieve 5 to 25 tokens/sec. He derives these figures from a 2019 study on edge robotics requirements.25
In terms of speed, that puts us 2-3 orders of magnitude behind the usefulness threshold. We can’t yet clear our human-level completed tasks threshold.
This still doesn’t factor in the constraint of high-quality token throughput - that you’re not just completing tasks faster than humans, but qualitatively better. That could be measured in terms of yield, defect rate, intervention rate, etc..

It’s not just about robotics
Let’s zoom out for a second. Why the obsession with robotics here?
Robotics is not just a sexy category. It’s a forcing function for rapid economic diffusion. By solving for energy-efficiency, you’re also solving for affordability in the economy’s most cost-sensitive sectors.
So when Prof. Yu mentions “ubiquitous edge intelligence for applications,” he’s talking about all kinds of economic applications, not just robots.
Consider one of the other keynote speakers: She Ying, founder of Haizhi Online.26 Haizhi is a digital platform connecting global industrial buyers with ~300K small and mid-sized factories.

In her world, AI’s (and technology in general) adoption by small and medium-sized manufacturing businesses is contingent on it being “understandable, useful, affordable, and effective.” That’s not a controversial statement, but it is rooted in customer empathy - all of her clients operate in intensely competitive local markets on razor-thin margins.
To that end, the concept of “SaaS subscription” as a revenue model does not really vibe in China. This is a big difference between American and Chinese consumers and businesses that’s often overlooked.
Many startups we spoke to are selling AI-enabled services by inking revenue-share contracts with their clients. Their strategy is to demonstrate that by partnering up, they can significantly boost their client’s sales, improving their competitiveness in highly crowded fields (manufacturing, textiles, etc.). Few, if any, were demanding up-front monthly subscription costs.
Incentives therefore are aligned for usefulness (high revenue growth for its partners) and affordability (to remain above breakeven), rather than passing usage costs onto customers.
For a great non-techie summary of this predisposition to ruthless optimization, check out Lesley Gao’s latest piece on Shaoyang and the ¥1 disposable lighter.

“Ubiquitous edge intelligence”
Let’s wrap up the keynote by summarizing Prof. Yu’s calls to action. His milestone for ubiquitous edge intelligence requires the following:
✅ GPT-4o/o1 grade intellect
✅ In a <7B parameter (read: sub-8GB) form factor
✅ At 100 - 2000 tokens/sec throughput (tau_sec)
✅ With >20 tokens/joule energy efficiency (eta)
This succeeds a migration from fused, modular systems (模块化系统 - mókuài huà xìtǒng) into a single end-to-end model (端到端模型 - duān dào duān móxíng) which can handle a variety of tasks and challenges.
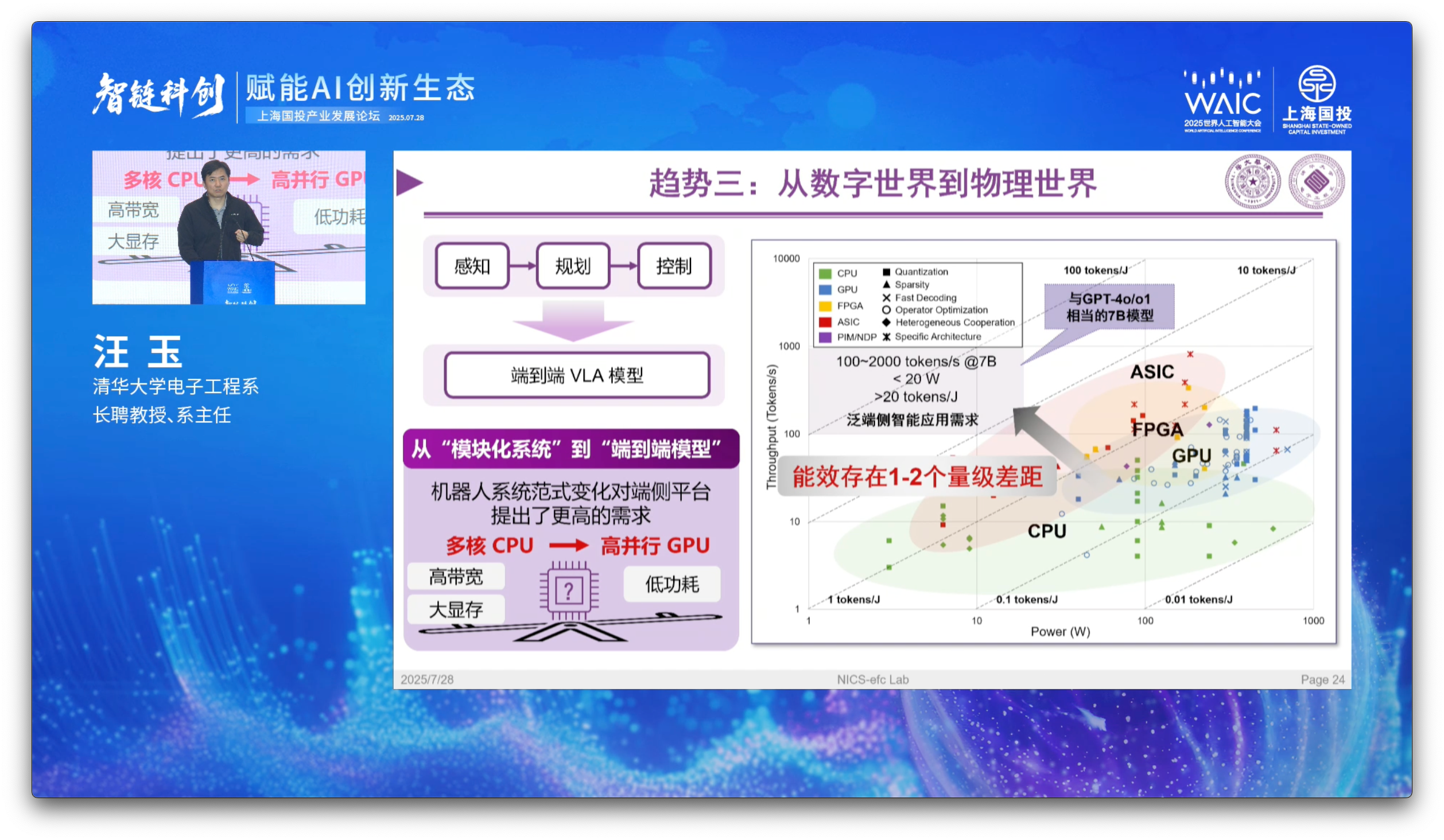
In the upper-left quadrant there is is a low-power, high-throughput domain which no tested combinations have been able to breach to date, let alone to do so with GPT-4o grade intellect.
As we’ve discussed, at a given iso-efficiency contour (~10 eta in best-case deployments), scaling alone does not take you closer to the upper-left quadrant. It just makes you more power-hungry.
End-to-end VLA models therefore require investments in hardware, model, and hosting infrastructure designs that considerably depart from scaling law theory. We need order of magnitude improvements in model and chip efficiencies.
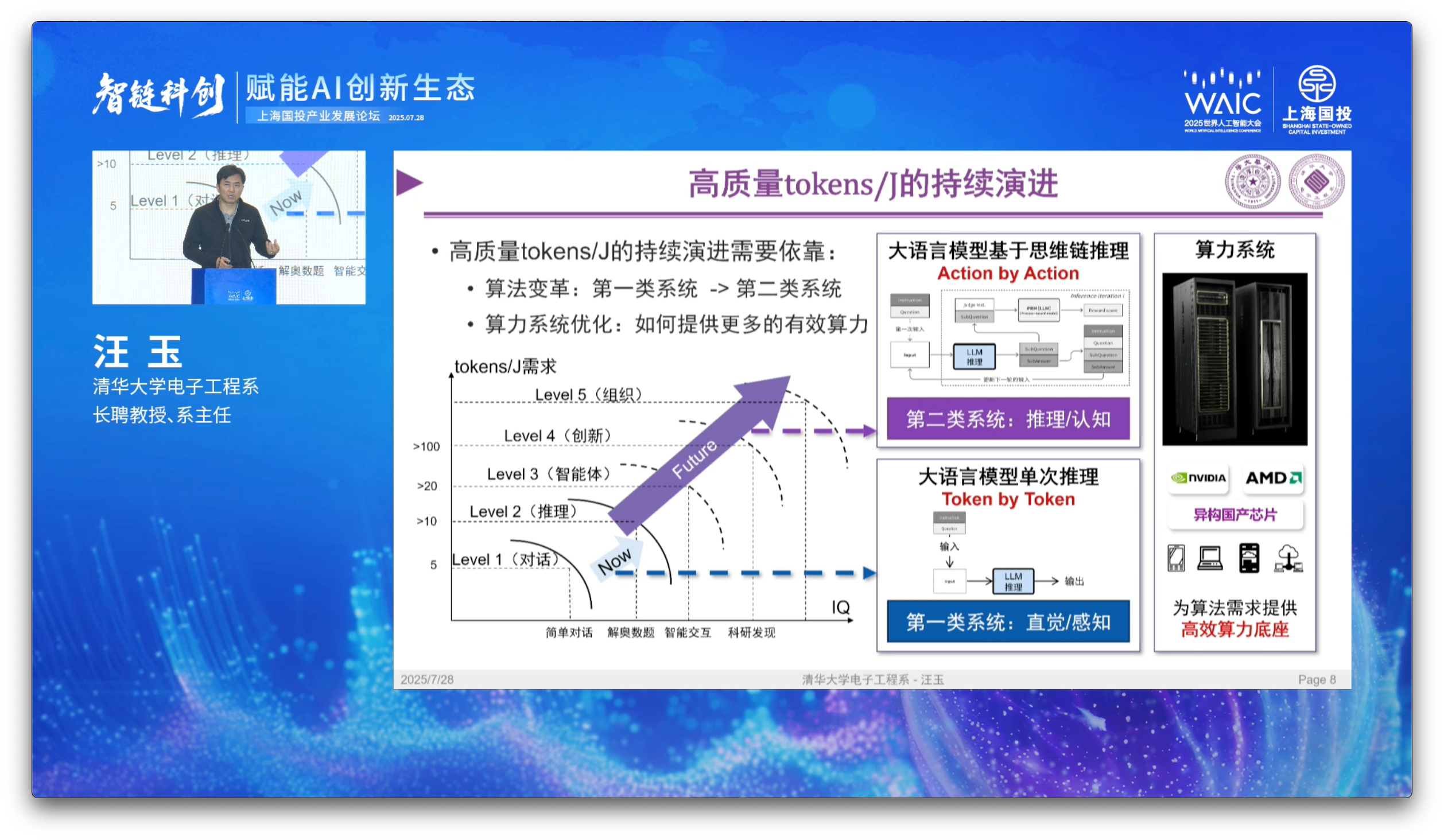
He groups these improvements into three buckets. They are not mutually exclusive, as each technique carries advantages in each bucket.
单次推理: Single-step inference (Token-by-Token)
思维链推理: Chain-of-thought reasoning (Action-by-Action)
算力系统: Hardware or system-level optimizations
Quantization (量化 - liànghuà)
Conserving memory bandwidth by casting model weights into reduced precision (e.g. FP32, FP16, integer-based formats, or new datatypes). Most hosts use quantization in inference today, but some research labs (like DeepSeek) are using mixed-precision in model training as well. Critical for fitting larger models into constrained memory footprints.
BinaryBERT was mentioned as an extreme demonstration.27
Sparsity (稀疏化 - xīshū huà)
Inspired by biological neural networks. “Deactivating” unused parameter weights in neural network activations. Even if a weight is set to “0”, the operation of multiplying that weight by another still contributes to arithmetic intensity. Critical for reducing computational overhead, and therefore, energy consumption.
This was a major focus area at the conference. Prof. Yu emphasized spent a fair amount of time detailing the benefits (maximize resource savings) and challenges (minimize degradation) from sparsification methods, and credited SparseGPT and DeepSeek-V2 for demonstrating its potential in post-training and training-aware approaches.2829
Fast Decoding
Speculative decoding and dynamic batching techniques to maximize token throughput within strict latency budgets. DeepSeek’s MLA attention mechanism is one such example. Critical for aligning with real-time requirements for inference with physical actuators.
In longer dialogues and super-long context windows (e.g. Kimi K2’s 1M token context window), inefficient decoding can carry serious memory loads and throughput penalties, making these techniques super valuable as user demands influence context length, memory, and so on.
Operator Optimization
Kernel fusion and hardware-aware operations (e.g., grouped GEMMs, hoisted activations) to minimize memory bottlenecks and exploit low-power silicon microarchitectures. Critical for achieving token-time and efficiency targets.
New Architectures
This could be either new chip designs like FPGA accelerators, neuromorphic chips, brain-inspired AI, and more.30 New memory-efficient model architectures like state-space models and task-specific language models are also increasingly in favor, especially for long context windows.3132
As you can tell from the earlier chart, novel chip designs (ASIC, PIM/NDP) are achieving considerably better token energy efficiency than general-purpose GPUs. However, they may not be suitable for all kinds of computations… which is why the next advancement is so important.
Heterogeneous Cooperation
Many research labs throughout China are now training or hosting models on heterogeneous rather than homogeneous chipsets. Distributing inference across hybrid chipsets balances the benefits of each platform, such as the flexibility of multi-core (多核) CPU with highly parallel (高并行) GPU throughput.
As an example, in this paper from the Shanghai AI Lab, the team demonstrates they can not only meet, but actually exceed token throughput for LLM training runs using mixed chip stacks:33
In practical production environments, lower-spec chips usually feature significantly lower pricing and reduced power consumption compared to their high-spec chips. By leveraging the HeteroPP framework for heterogeneous training, which integrates both lower-spec and high-spec chips, we can achieve training performance comparable to or even exceeding that of homogeneous high-spec setups, which preserves high performance and reduces overall training costs.
Ding Tang, et al., 2025.
Successful implementations here not only yield energy efficiency improvements - they de-link China’s chip ecosystem from the chip export bottlenecks, as they’re no longer tied to performance of homogeneous leading-edge GPUs.
Takeaways
Alright, that was a lot. Let’s wind it down and bring it all back.
I started this post by introducing energy-compute theory, its inputs, and its constraints. Then, we investigated how China’s AI ecosystem has been leaning full-tilt into this development framework, in comparison to the US’ preference for IQ-maxxing.
What are the implications if these ecosystems continue on those development tracks? Here are three to follow:
Open-source continues to raise Qmin.
Strategically, continuing to release more and more capable open-source models raises the baseline for expected intelligence levels in deployed models. But without commensurate investments in model or chip optimizations, energy efficiency will drop, and inference costs will rise.
GPT-5 may already be a casualty here. Some skeptics consider its launch a cost-cutting measure rather than a material improvement in capability - an ill-conceived attempt to abstract reasoning effort and save on inference costs by nerfing the consumer experience for 1BN users in the process.34
Chip wars diverge national eta values.
Thanks to recent shenanigans, Chinese domestic semiconductor independence is now a matter of when, not if.3536
As the market leader, NVIDIA will continue pushing out more capable chips, but every release since Volta has only averaged a 1.53x improvement in performance-per-watt. So it’s doubtful that homogeneous NVIDIA systems will achieve the energy efficiency values necessary to meet audacious economic diffusion targets (to say nothing about developer friendliness towards CUDA - NVIDIA still takes the crown there).
 from V100 to Rubin (Corrected B300)")
Hyperscalers have been hard at work developing their own custom silicon in order to reduce their total cost of ownership (TCO), of which energy use is a major factor.37 Even in the most resource-rich playgrounds, efficiency matters.
The post-WAIC establishment of Model-Chips Ecosystem Innovation Alliance is an encouraging signal that integrative R&D circles in China may spur joint advancements in model and chip energy efficiencies. The initial listed members cut across each category:38
Models: StepFun
Infrastructure: Infinigence AI, SiliconFlow
Hardware: Huawei Ascend, MetaX, Biren, Enflame, Iluvatar CoreX, Cambricon, Moore Threads
China surpasses the US in energy-compute budgets (E).
This will likely happen regardless. China already enjoys a 6,000 terawatt-hour (TWh) per year advantage over the United States today, and that may rise to 10,000 TWh by the end of the decade.39
While the US spends a larger proportion of power on data centers today at 327 TWh vs. China’s 163 TWh in 2024, that budget is impossible to ignore… it’s the equivalent of the cumulative TWh consumption of the entire OECD.4041
The Triple Product Advantage
Single-dimension scaling has plateaued; the limits of pure parameter growth are now pretty much mainstream.
Unless the US keeps pace on all three fronts - novel model architectures, high-efficiency silicon, and plenty of power - China’s AI output will compound past ours in economic value.
It will be gradual at first, then sudden. In energy-compute theory these levers don’t add, they multiply: a modest gain in each lever (energy, efficiency, IQ) produces a polynomial jump in the total. This is called a triple-product advantage.
Is this doom and gloom for the American AI ecosystem? Not at all, just a call to action. Perhaps we should be thinking less like software venture capitalists and more like energy companies.42 That’s what energy-compute theory is meant to capture.
Simply put, as model intelligence commoditizes thanks to scaling law limitations, we may finally be entering the era of ruthless optimization.
Some might call it an “AI Winter”… I call it the start of something great.

“The proposal, put to co-founder Andrew Tulloch, included a billion-dollar package that could exceed $1.5 billion over six years with bonuses taken into account, sources told the WSJ.” https://www.itpro.com/technology/artificial-intelligence/deepmind-ceo-demis-hassabis-thinks-metas-multi-billion-dollar-hiring-spree-shows-its-scrambling-to-catch-up-in-the-ai-race
“Blitzscaling”, Chris Yeh and Reid Hoffman, 2016. Strong recommend. https://hbr.org/2016/04/blitzscaling
Specifically, he said that the opportunity with artificial general intelligence is so incomprehensibly enormous that if OpenAI manages to crack this particular nut, it could “maybe capture the light cone of all future value in the universe.” https://techcrunch.com/2019/05/18/sam-altmans-leap-of-faith/
Jeffrey Ding, 2024. Read it! https://www.amazon.com/Technology-Rise-Great-Powers-International/dp/0691260346
NVIDIA H200 datasheet. https://nvdam.widen.net/s/nb5zzzsjdf/hpc-datasheet-sc23-h200-datasheet-3002446
Derived from Viperatech listing. https://viperatech.com/product/nvidia-hgx-h20/
We could add a line in here about how BeanUSA’s CEO just hired a Michelin-rated barista for a 6-year, $1.5B contract - you get the point.
“OpenAI announces 80% price drop for o3, it’s most powerful reasoning model.” Venturebeat, 2025. https://venturebeat.com/ai/openai-announces-80-price-drop-for-o3-its-most-powerful-reasoning-model/
This story has way overstayed its welcome, but have fun with three what-if epilogues:
New product launch. BeanUSA unveils its successor brew, the BeanPT-5. Initial reviews are positive, but more customers are reporting its taste is somewhat diluted, and some brews take longer to make. Insiders later reveal than BeanUSA is algorithmically varying the “effort” of bean flavor in each cup depending on the customer’s tone at the counter. The net effect does lower unit costs, but the brew’s reputation suffers.
Gridlock. BeanUSA files for a permit to triple its floorplan and boost foot traffic. The electric utility rejects the plan, stating the grid can’t support the extra power from the 40 new H200s, and it will take 3 to 8 years to get more power.
Nuclear moonshot. BeanUSA announces they are bypassing the grid application process and are installing a small modular nuclear reactor (SMR) to support up to 1000 new H200s… but the SMR will take 7 years to license, develop, test, and install.
https://www.ciphernews.com/articles/the-u-s-and-china-drive-data-center-power-consumption/
https://batteryswapcabinet.com/powering-the-future-how-the-humanoid-robot-boom-is-reshaping-the-lithium-battery-industry/
https://en.wikipedia.org/wiki/Kardashev_scale
LARGE LANGUAGE MODEL INFERENCE ACCELERATION: A COMPREHENSIVE HARDWARE PERSPECTIVE. Jinhao Li et al., 2024. https://arxiv.org/pdf/2410.04466v2
They don’t melt in practice, but you won’t be getting anything out of them - most accelerators’ software shuts down the card until it’s back in a safe operating temperature range. https://www.servermania.com/kb/articles/gpu-temperature-range-guide
Average adults apparently read up to 350 wpm. We’ll say that’s 75th percentile. https://scholarwithin.com/average-reading-speed
“…reasoning models produce responses 5 to 10 times longer than the similar sized instruct models, even for questions when both types of models can correctly solve.“ CoThink: Token-Efficient Reasoning via Instruct Models Guiding Reasoning Models. Siqi Fan, et al., 2025. https://arxiv.org/pdf/2505.22017v1
Human Latency Conversational Turns for Spoken Avatar Systems. Jacoby et al., 2024. https://arxiv.org/pdf/2404.16053v1
Artificial Analysis Language Model API Endpoint Leaderboard, Medium models filter. Accessed 8/13/2025. https://artificialanalysis.ai/leaderboards/providers?size_class=medium
Derived from “泛端侧智能应用” - “泛" meaning “ubiquitous”, “端侧” meaning edge-side or “edge”, 智能 derived from artificial intelligence (人工智能), and 应用 meaning “applications.”
Scaling Laws of Motion Forecasting and Planning: A Technical Report. Baniodeh et al., 2025. https://arxiv.org/pdf/2506.08228v1
See BatterySwapCabinet.
Benchmarking Reasoning Models: From Tokens to Answers. AMD, 2025. https://rocm.blogs.amd.com/artificial-intelligence/benchmark-reasoning-models/README.html
前沿应用一机器人智能的基本需求,参考自 (“The basic requirements for cutting-edge applications of robotic intelligence, refer to”) Deray, Jeremle, Joan Sola, and Juan Andrade-Cetto, "Joint on-manifold self-calibration of odometry model and sensor extrinsics using pre-Integration." 2019 European Conference on Mobile Robots (ECMR). IEEE, 2019. https://ieeexplore.ieee.org/document/8870942
She Ying: Promote more small and medium-sized factories to be "seen" and "selected." INEWS, 2025. https://inf.news/en/economy/497374f93538b62172833997d324324e.html
BinaryBERT: Pushing the Limit of BERT Quantization. Haoli Bai, et al., 2020. https://arxiv.org/abs/2012.15701
SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot. Frantar, Alistarh, 2023. https://arxiv.org/pdf/2301.00774
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. DeepSeek-AI, et al., 2024. https://arxiv.org/abs/2405.04434
China AI-Brain Research. CSET, 2020. https://cset.georgetown.edu/publication/china-ai-brain-research/
Mamba: Linear-Time Sequence Modeling with Selective State Spaces. Albert Gu, Tri Dao, 2023. https://arxiv.org/abs/2312.00752
Fastino Launches TLMs (Task-Specific Language Models) with $17.5M Seed Round Led by Khosla Ventures. Yahoo! Finance, 2025. https://finance.yahoo.com/news/fastino-launches-tlms-task-specific-215600480.html
H2: Towards Efficient Large-Scale LLM Training on Hyper-Heterogeneous Cluster over 1,000 Chips. Ding Tang, et al., 2025. https://arxiv.org/pdf/2505.17548v1
Hacker News, accessed 8/12/2025. https://news.ycombinator.com/item?id=44851557
NVIDIA and AMD to pay 15% of China chip sale revenues to US government. Financial Times, 8/10/2025. https://www.ft.com/content/cd1a0729-a8ab-41e1-a4d2-8907f4c01cac
China cautions tech firms over NVIDIA H20 AI chip purchases, sources say. Reuters, 8/12/2025. https://www.reuters.com/world/china/china-cautions-tech-firms-over-nvidia-h20-ai-chip-purchases-sources-say-2025-08-12/
The Rise of Custom AI Chips: How Big Tech is Challenging NVIDIA’s Dominance. Aranca, 4/28/2025. https://www.aranca.com/knowledge-library/articles/investment-research/the-rise-of-custom-ai-chips-how-big-tech-is-challenging-nvidias-dominance
Chinese semiconductor, AI firms form pact as NVIDIA faces inquiry on H20 chip’s security. SCMP, 7/31/2025. https://www.scmp.com/tech/tech-war/article/3320301/chinese-semiconductor-ai-firms-form-pact-nvidia-faces-inquiry-h20-chips-security
AsianPower, 8/7/2025. https://asian-power.com/news/chinas-power-consumption-breach-13000-twh-in-2030
Monthly Electricity Statistics, IEA, 7/17/2025. https://www.iea.org/data-and-statistics/data-tools/monthly-electricity-statistics
Energy and AI, IEA, 4/10/2025. https://iea.blob.core.windows.net/assets/dd7c2387-2f60-4b60-8c5f-6563b6aa1e4c/EnergyandAI.pdf
“Hydraulically Fractured Horizontal Wells: A Technology Poised To Deliver Another Energy-Related Breakthrough of Enormous Scale.” Greg Leveille, Journal of Petroleum Technology, 2/1/2024. https://jpt.spe.org/guest-editorial-hydraulically-fractured-horizontal-wells-a-technology-poised-to-deliver-another-energy-related-breakthrough-of-enormous-scale
Great article! Thanks for sharing!
Fascinating piece. Just one question: On what basis are you asserting IQ is commoditized? Recognizing we’re in a period of plateau, with what conviction can we say there’s no architectural breakthrough on the horizon?